K8S不支持长连接的负载均衡,所以负载可能不是很均衡。如果你在使用HTTP/2,gRPC, RSockets, AMQP 或者任何长连接场景,你需要考虑客户端负载均衡。
TL;DR: Kubernetes doesn’t load balance long-lived connections, and some Pods might receive more requests than others. If you’re using HTTP/2, gRPC, RSockets, AMQP or any other long-lived connection such as a database connection, you might want to consider client-side load balancing.
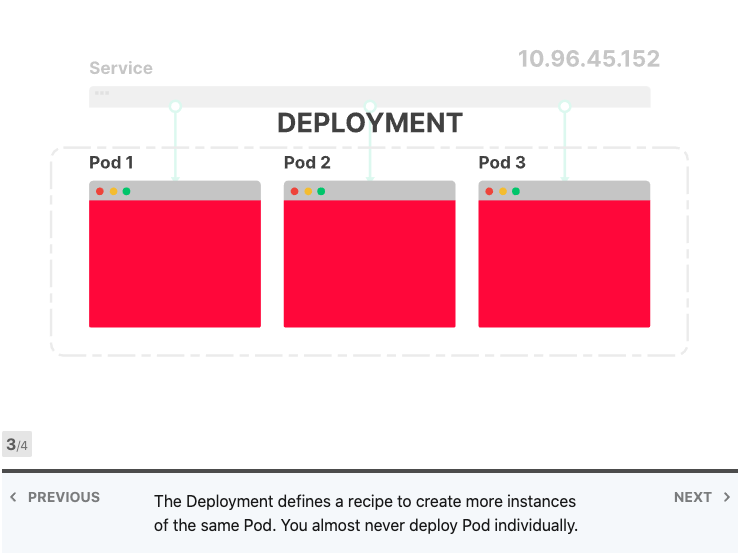
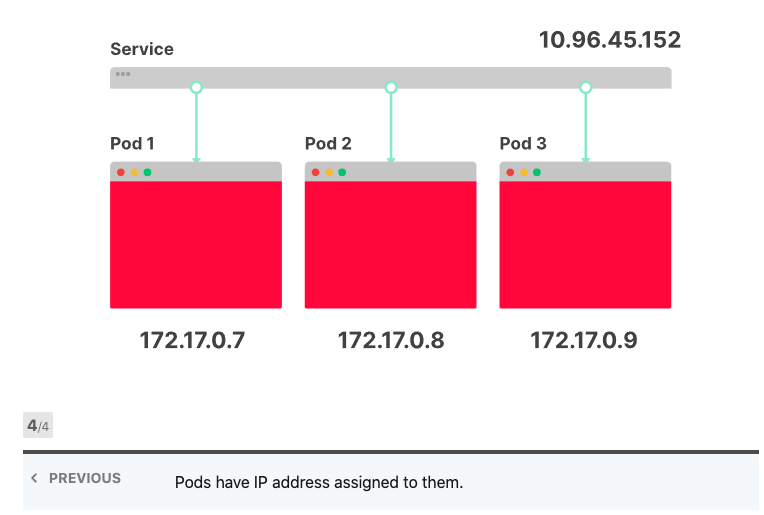
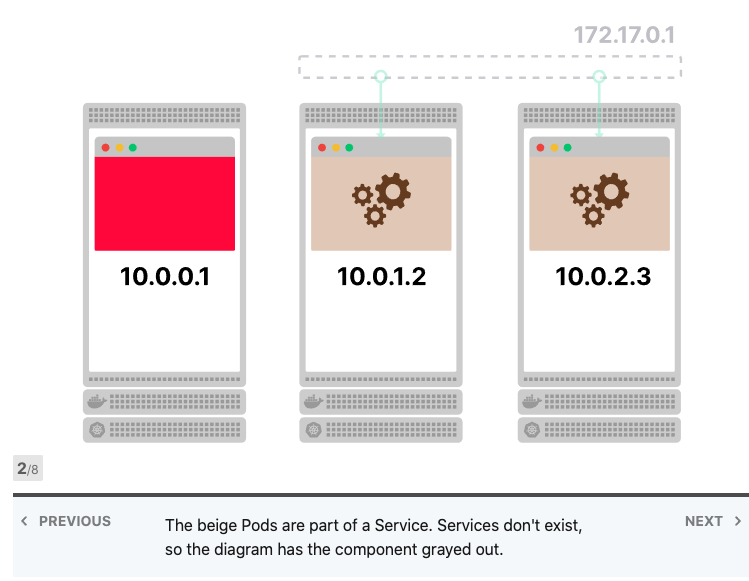
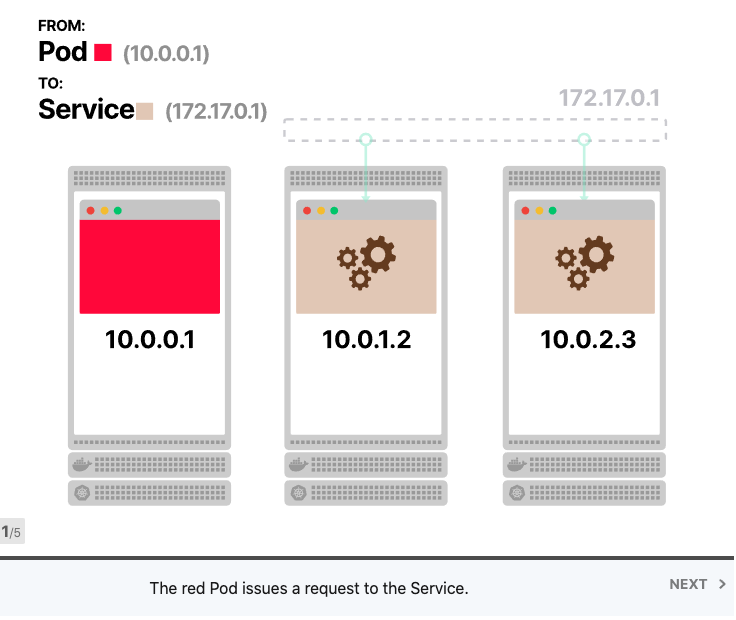
Kubernetes提供了两种方便的抽象来部署应用程序:Services 和 Deployments。 Deployments描述了在任何给定时间应运行哪种类型以及多少个应用程序副本的方法。每个应用程序都部署为Pod,并为其分配了IP地址;另一方面,Services类似于负载平衡器。它们旨在将流量分配给一组Pod。
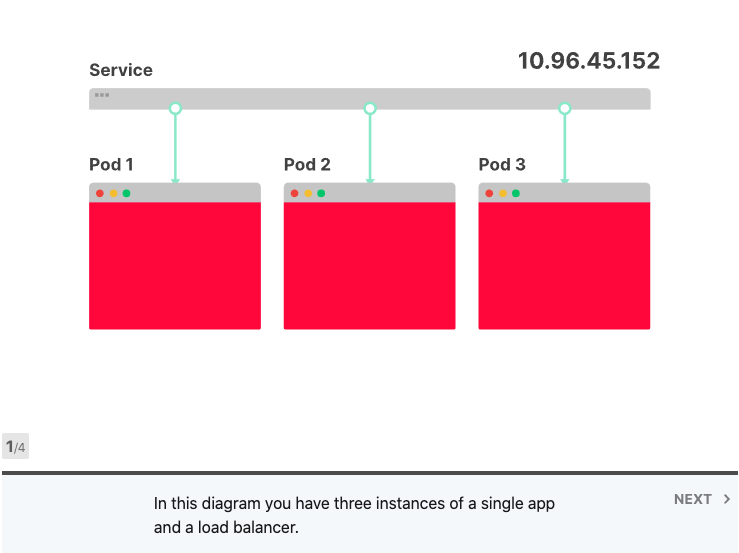
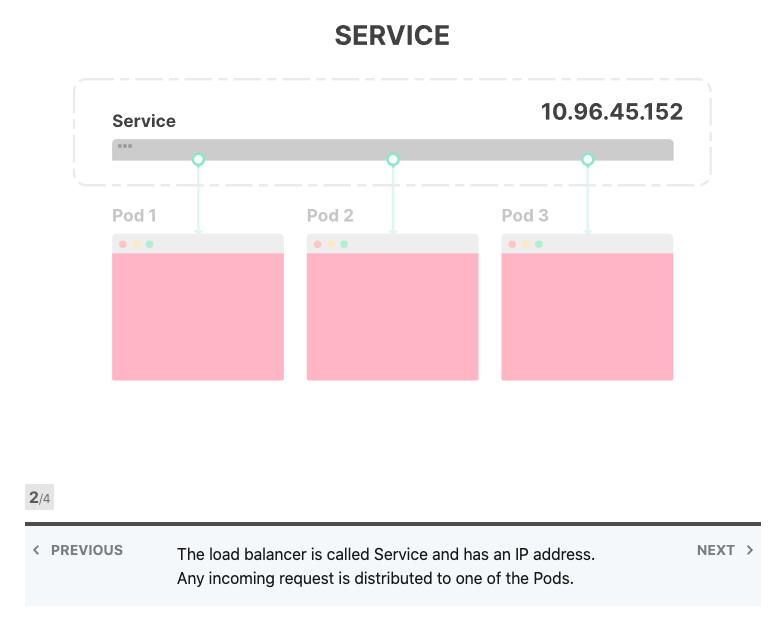
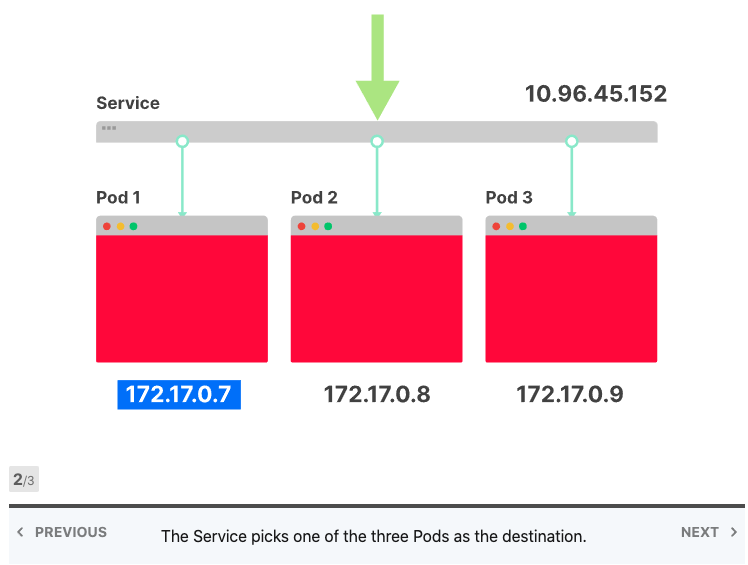
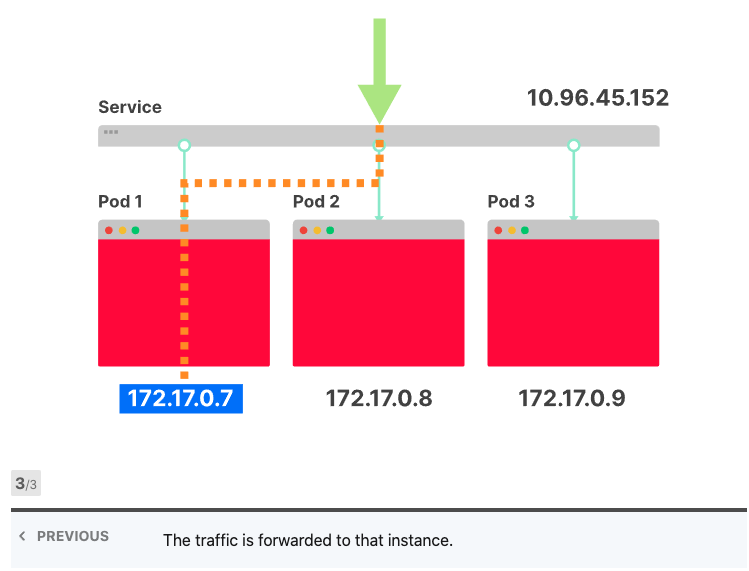
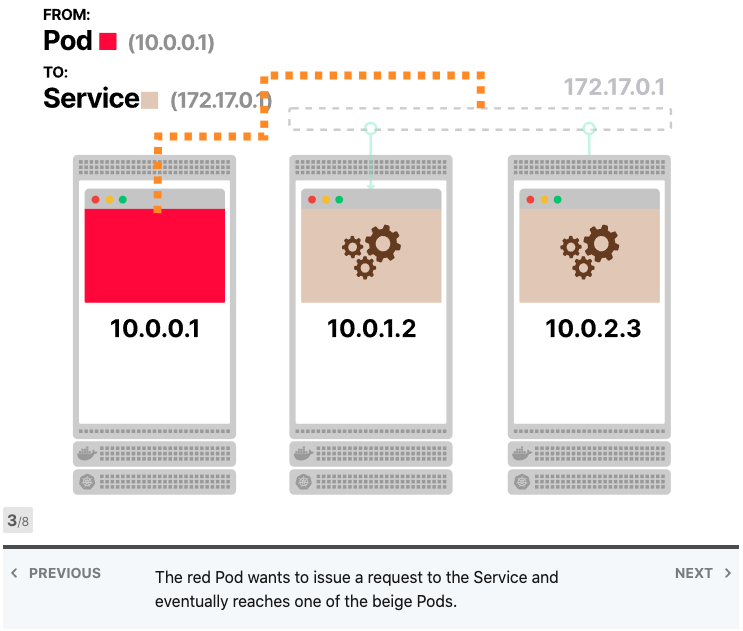
将Services视为IP地址的集合通常很有用。每次您对Services提出请求时,都会从该列表中选择一个IP地址并将其用作目的地。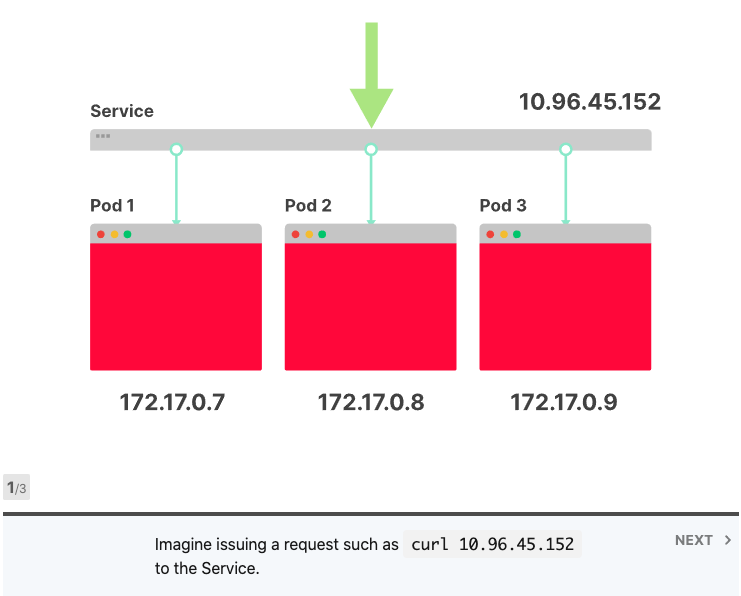
如果您有两个应用程序(例如前端和后端),则可以为每个应用程序使用Deployment和Service,然后将它们部署在集群中。
当前端应用发出请求时,不需要知道有多少Pod连接到后端服务;前端应用程序也不知道后端应用程序的各个IP地址。当它想要发出请求时,该请求将发送到IP地址不变的后端服务。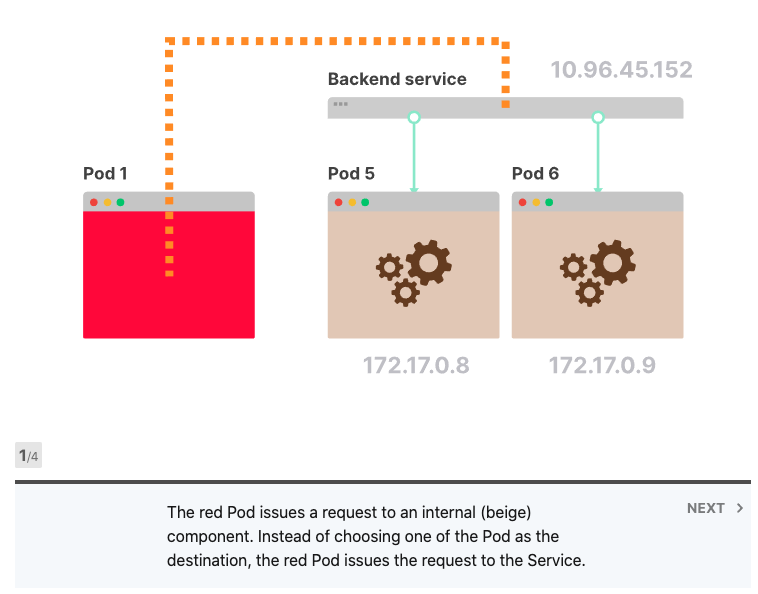
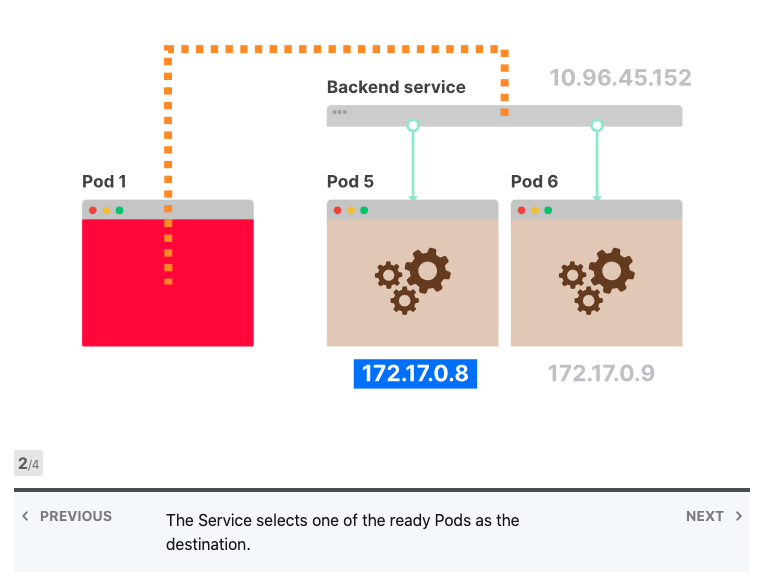
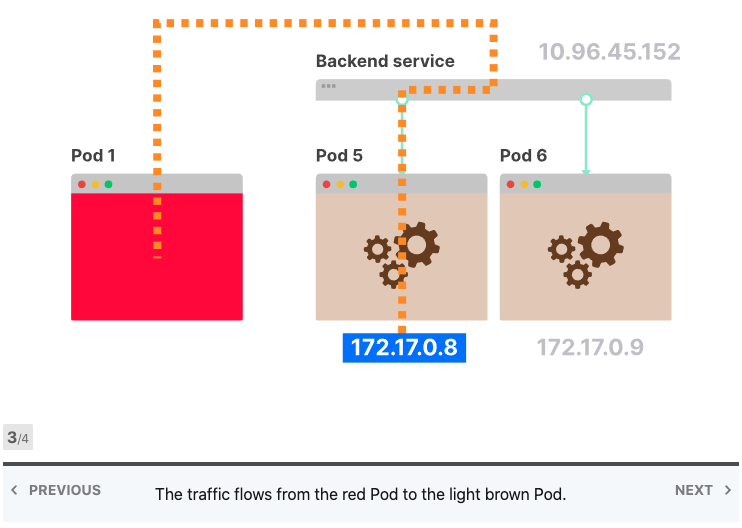
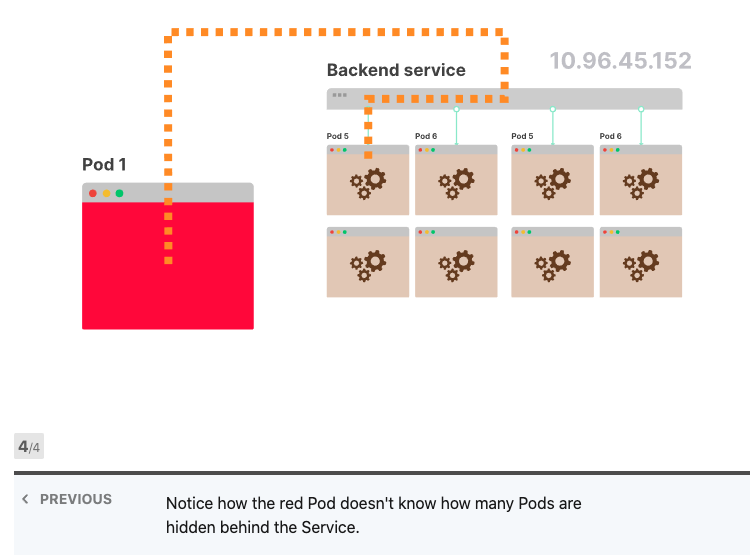
Kubernetes Services中的负载平衡
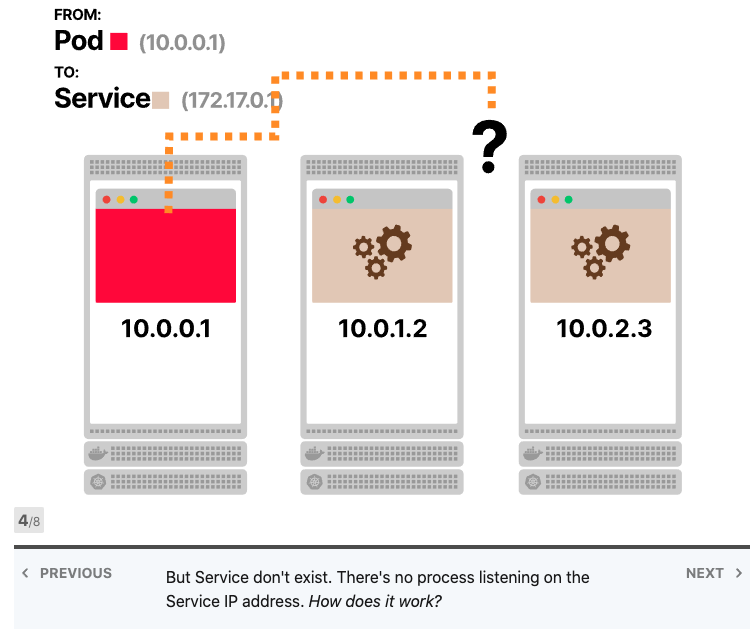
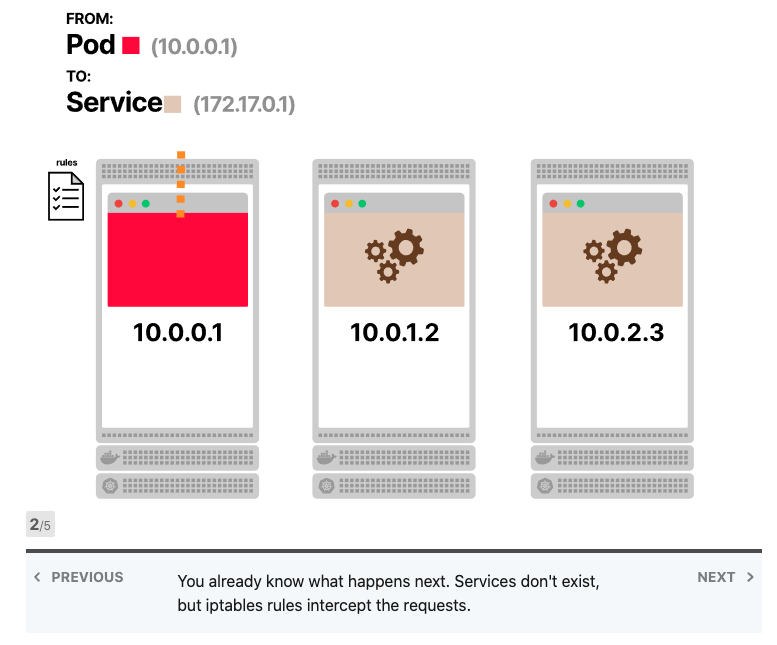
Kubernetes Services不存在,没有进程监听服务的IP地址和端口。
您可以通过访问Kubernetes集群中的任何节点并执行netstat -ntlp来检查是否存在这种情况。
甚至在任何地方都找不到IP地址,Services的IP地址由控制器管理器中的控制平面分配,并存储在数据库etcd中。然后,另一个组件将使用相同的IP地址:kube-proxy。
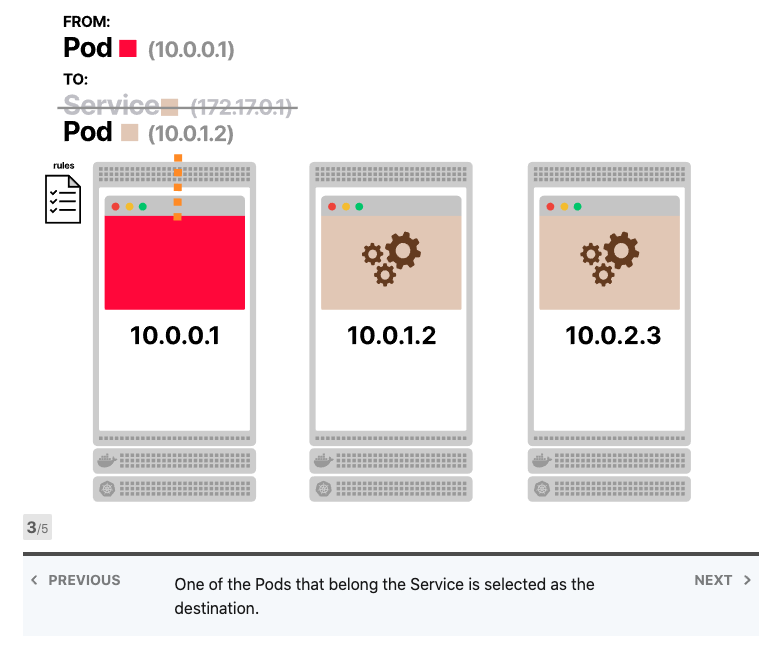
Kube-proxy读取所有Services的IP地址列表,并在每个节点中写入一组iptables规则。这些规则的意思是:“如果看到此Services IP地址,则改写请求并选择Pod之一作为目的地”。Services IP地址仅用作占位符-这就是为什么没有进程监听IP地址或端口的原因。
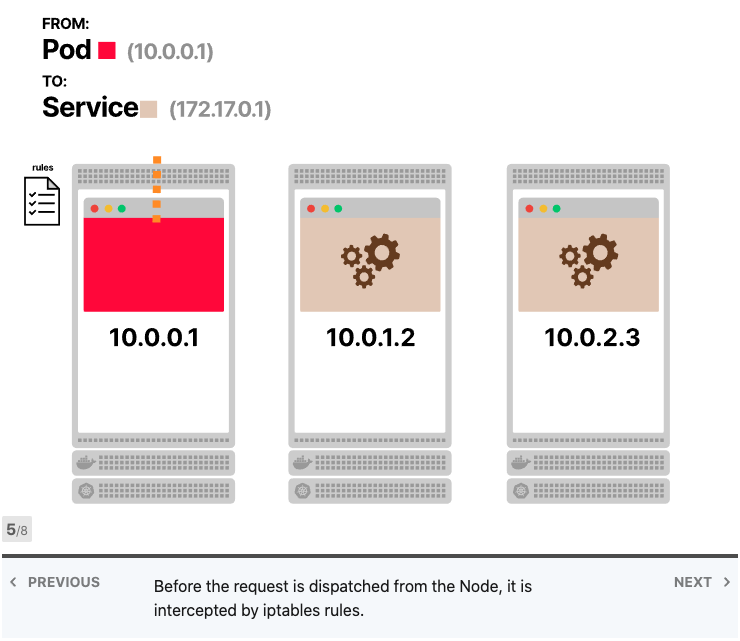
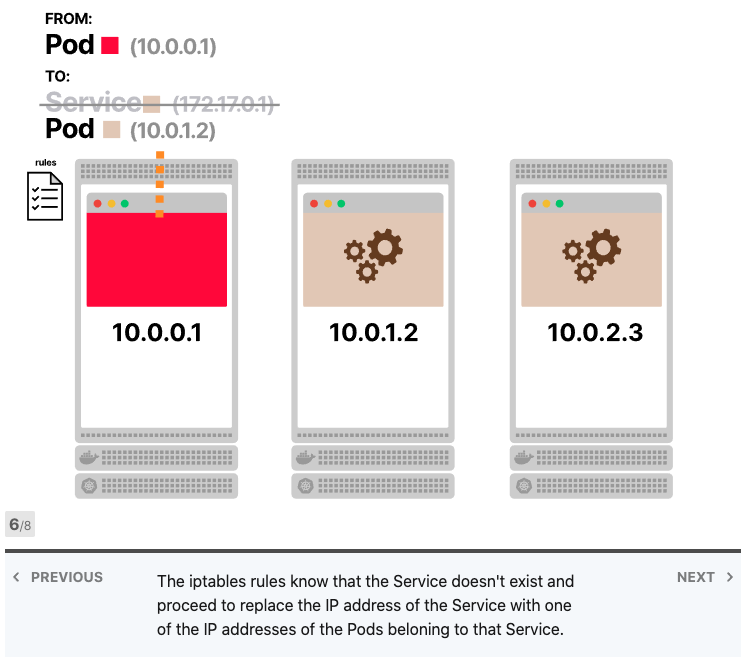
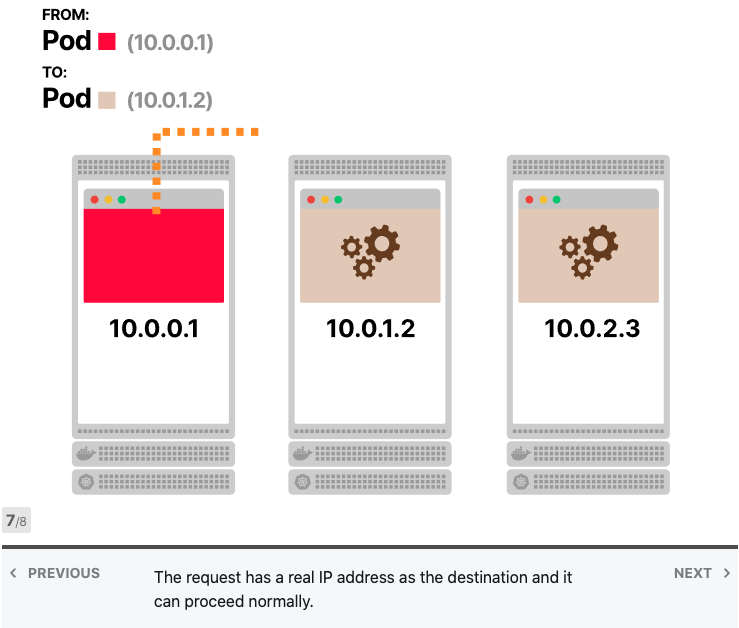
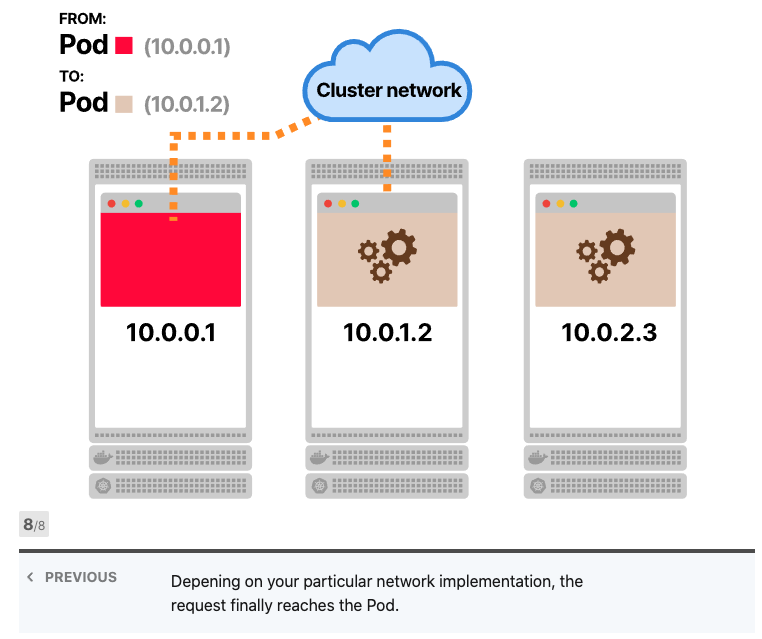
iptables是否使用轮询?不,iptables主要用于防火墙,并且其目的不是进行负载平衡。但是,您可以制定一套聪明的规则,使iptables像负载均衡器一样工作。而这正是Kubernetes中发生的事情。
如果您有三个Pod,则kube-proxy编写以下规则:
- 选择Pod 1作为目的地,可能性为33%。 否则,移至下一条规则
- 选择Pod 2作为目的地,可能性为50%。 否则,请移至以下规则
- 选择Pod 3作为目的地(没有可能性)
复合概率是Pod 1,Pod 2和Pod 3都有三分之一的机会被选中(33%)。
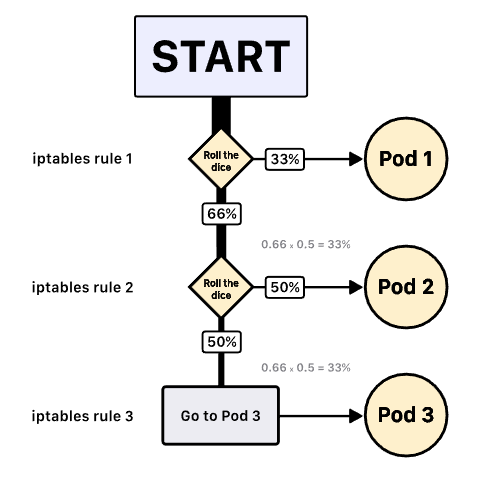
Iptables使用随机模式的statistic模块。所以负载均衡算法是随机的。
长期连接不会在Kubernetes中扩展(scale)
从前端到后端启动每个HTTP请求时,都会打开和关闭一个新的TCP连接。
如果前端每秒向后端发出100个HTTP请求,则在该秒内将打开和关闭100个不同的TCP连接。
如果打开TCP连接并将其重新用于任何后续HTTP请求,则可以改善延迟并节省资源。
HTTP协议具有称为HTTP保持活动或HTTP连接重用的功能,该功能使用单个TCP连接发送和接收多个HTTP请求和响应。
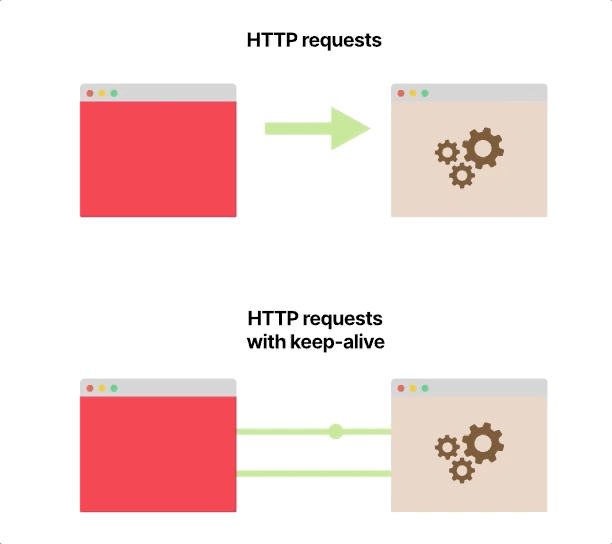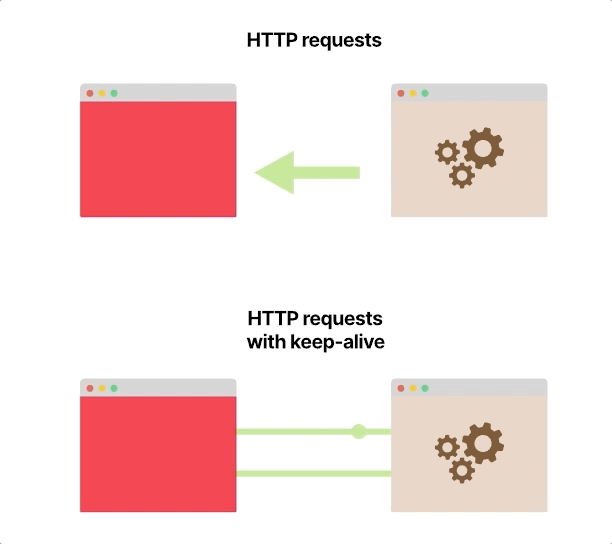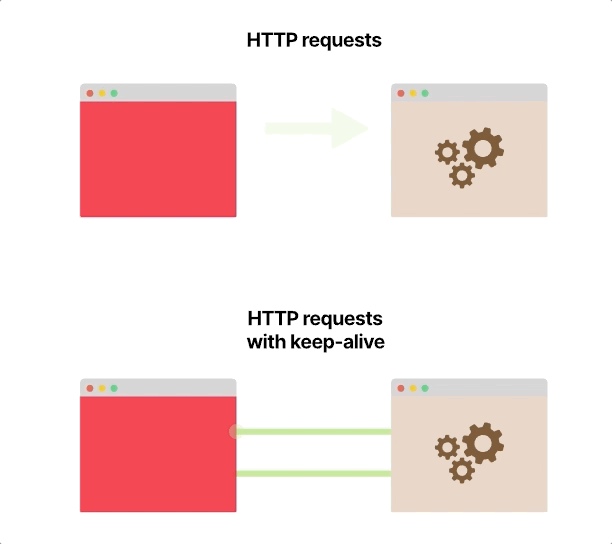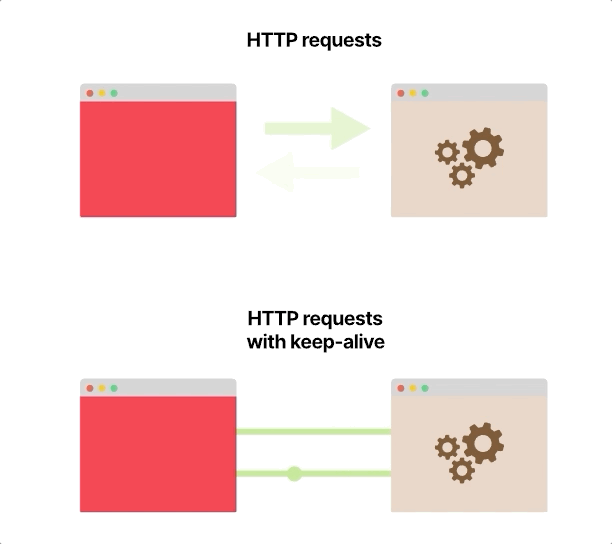
它不是现成的;您的服务器和客户端应该配置为使用它,这种改变本身很简单,而且在大多数语言和框架中都可以使用。
当您在Kubernetes服务中使用keep-alive时会发生什么?
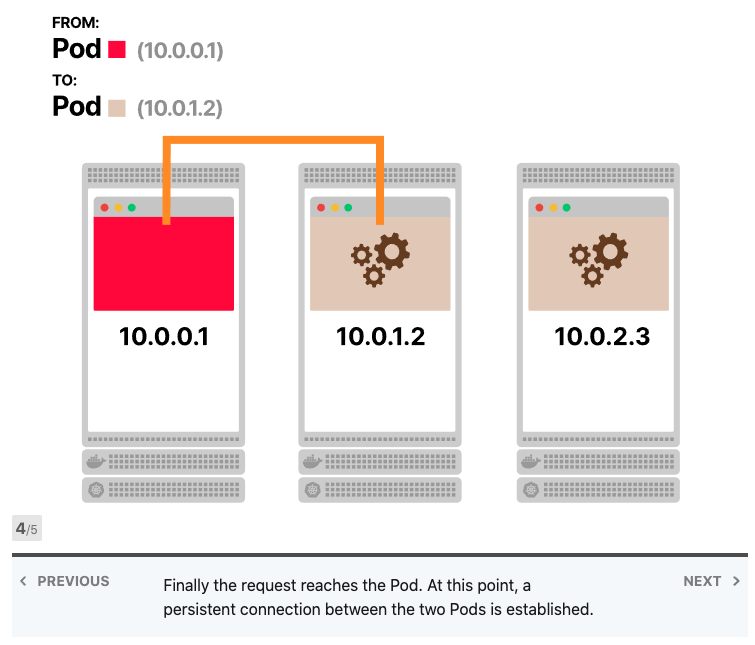
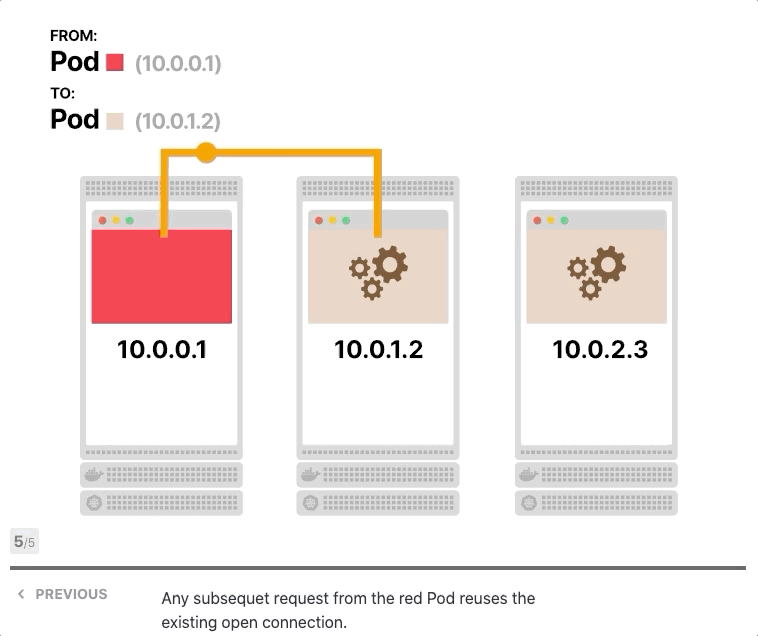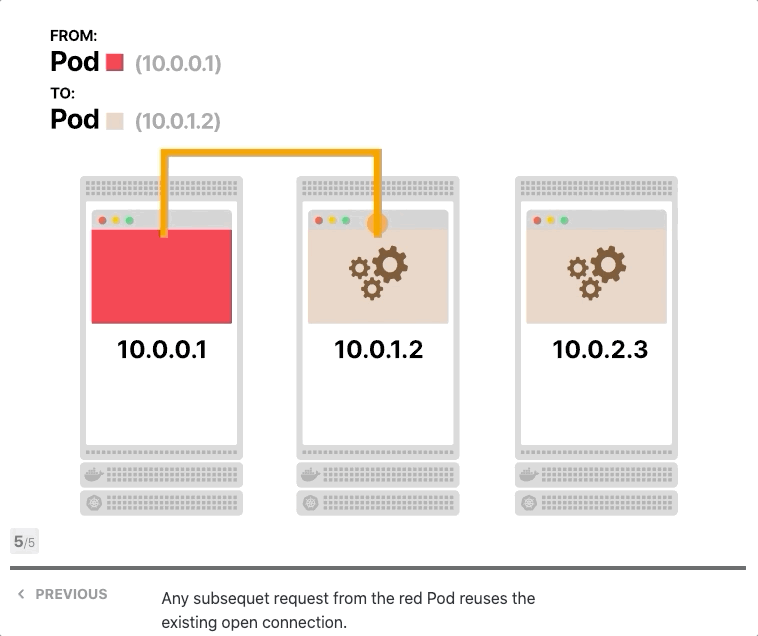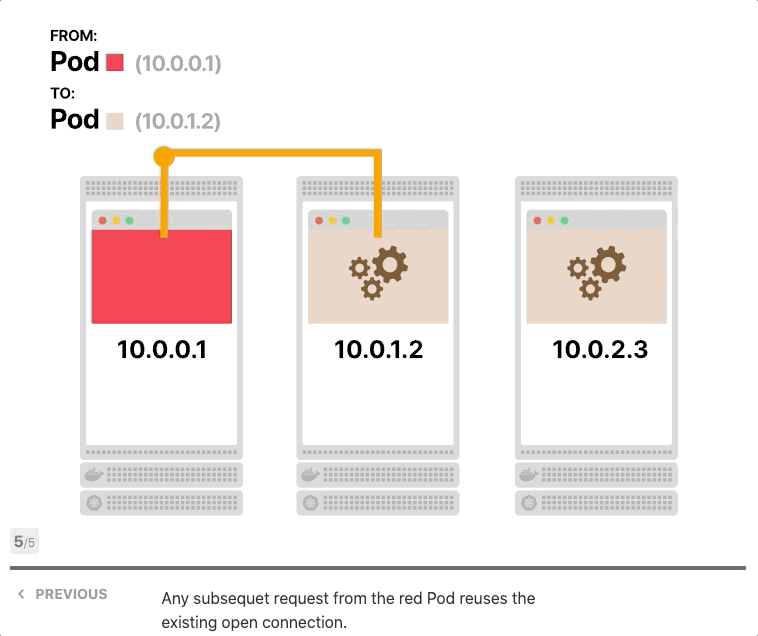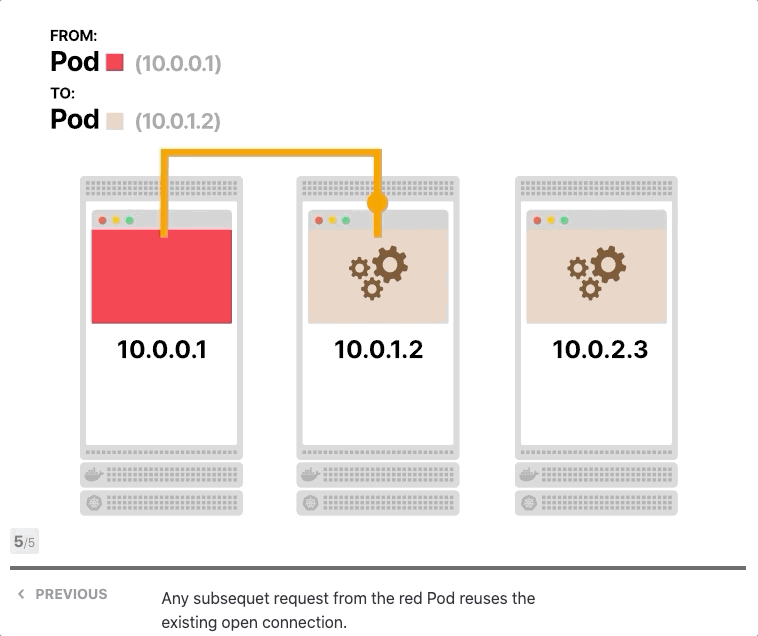
让我们假设前端和后端都支持keep-alive,您有一个前端实例和三个后端副本,前端向后端发出第一个请求并打开TCP连接,请求到达服务,其中一个Pod被选择为目的地,后端Pod响应,前端接收响应。但是,它没有关闭TCP连接,而是为后续的HTTP请求保持打开状态。
当前端发出更多请求时会发生什么? 他们被送到同一个Pod。
难道iptables不应该分配流量吗? 事实上、它打开了一个TCP连接,第一次调用了iptables规则,三个Pod中的一个被选为目的地,由于所有后续请求都通过同一个TCP连接进行传输,因此iptables不再被调用。
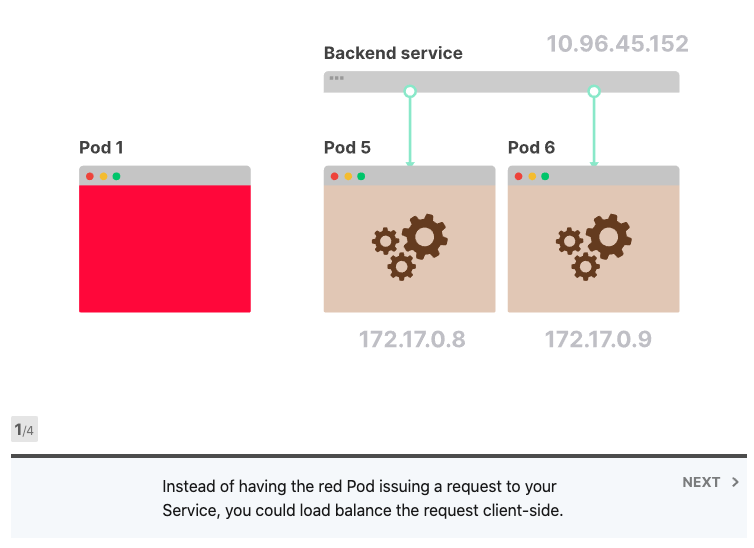
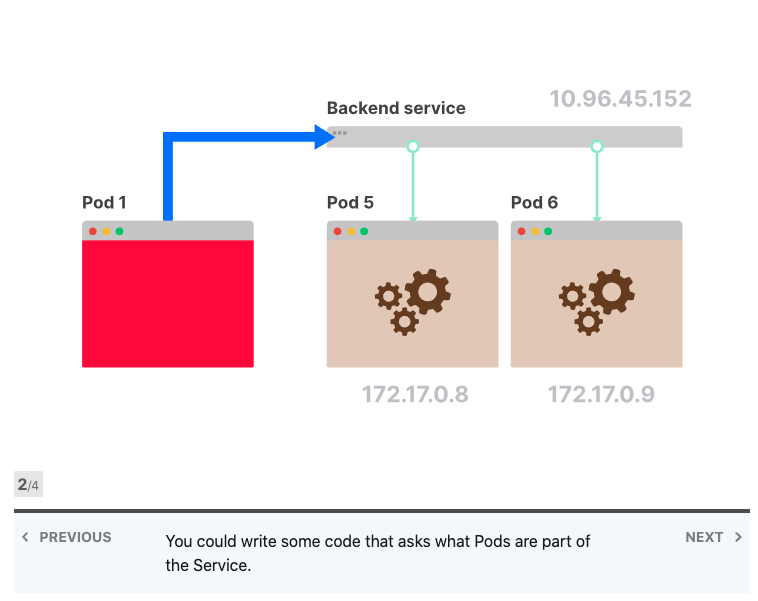
它可以修复吗? 由于Kubernetes不知道如何对持久性连接进行负载平衡,因此您可以自己介入并对其进行修复。服务是IP地址和端口的集合,通常称为端点。您的应用程序可以从服务中检索端点列表,并决定如何分发请求。
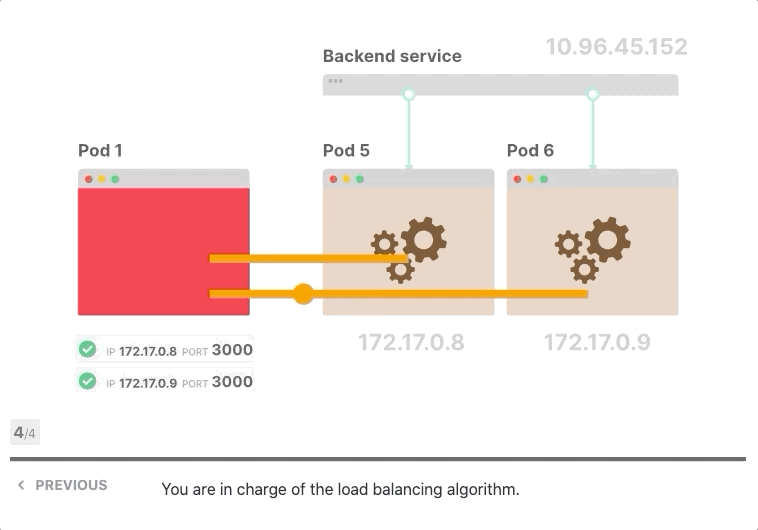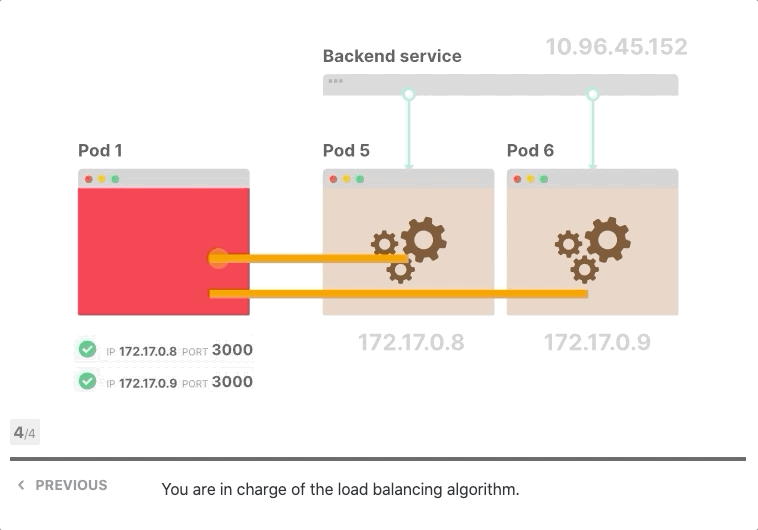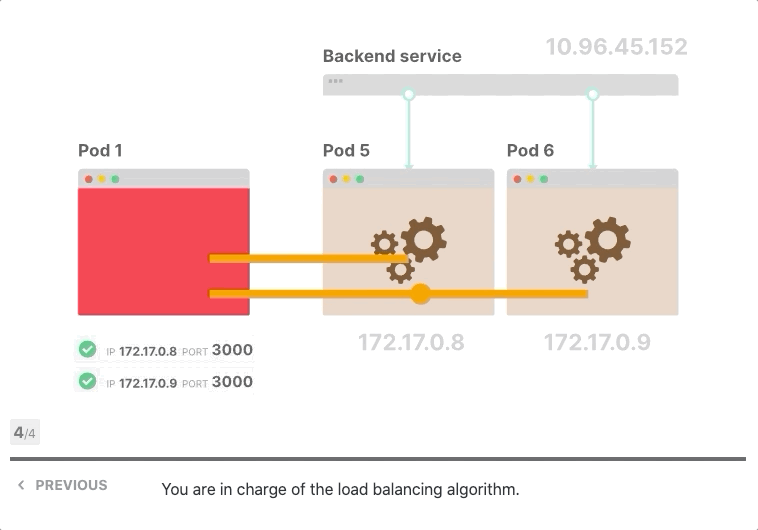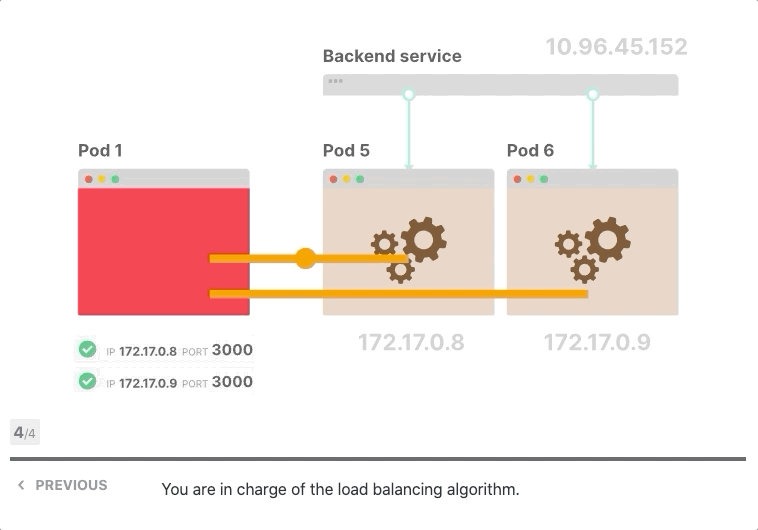
首次尝试时,您可以打开与每个Pod的持久连接,并对它们进行轮询请求。或者,您可以实施更复杂的负载平衡算法。
执行负载平衡的客户端代码应该遵循以下逻辑:
从服务中检索端点列表
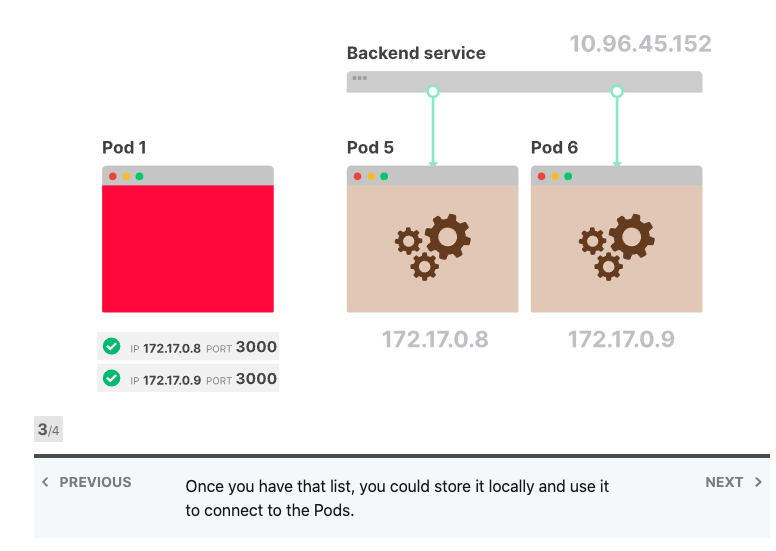
对于它们中的每一个,打开一个连接并保持其打开状态
当您需要发出请求时,选择一个打开的连接
定期刷新端点列表,并删除或添加新连接
客户端负载均衡
HTTP不是唯一可以受益于长期TCP连接的协议。如果您的应用程序使用数据库,则每次您要检索记录或文档时都不会打开和关闭连接。相反,TCP连接仅建立一次并保持打开状态。
如果使用服务将数据库部署在Kubernetes中,则可能会遇到与上一个示例相同的问题。数据库中有一个副本的利用率高于其他副本。Kube-proxy和Kubernetes不利于平衡持久连接。相反,您应该注意负载均衡对数据库的请求。
根据用于连接数据库的库,您可能有不同的选择。
您可以想象,还有其他几个协议可以在长期存在的TCP连接上工作。这里你可以读到一些例子:
- Websockets和安全Websockets
- HTTP / 2
- gRPC
- RSockets
- AMQP
您可能会认识到上面的大多数协议。因此,如果这些协议非常流行,为什么没有标准的负载均衡解决方案呢? 为什么必须将逻辑移入客户端? Kubernetes中是否有本机解决方案?
Kube-proxy和iptables旨在涵盖Kubernetes集群中最流行的部署用例,但是它们大多是为了方便。
如果您使用的是公开REST API的Web服务,那么您很幸运-该用例通常不会重用TCP连接,并且可以使用任何Kubernetes服务。但是,一旦开始使用持久的TCP连接,就应该研究如何将负载平均分配到后端。
Kubernetes没有开箱即用地涵盖该特定用例,但是有些东西可能会有所帮助。
负载平衡Kubernetes中的长连接
Kubernetes有四种不同的服务:
- ClusterIP
- NodePort
- loadbalance
- Headless
前三个服务都有一个虚拟IP地址,kube-proxy使用该地址创建iptables规则。但Headless服务是所有服务的基本组成部分。 headless服务没有分配的IP地址,只是一种收集Pod IP地址和端口(也称为端点)列表的机制。其他所有服务都建立在Headless服务之上。
ClusterIP服务是一项Headless 服务,具有一些附加功能:
- 控制平面为其分配IP地址
- kube-proxy遍历所有IP地址并创建iptables规则
因此,您可以完全忽略kube-proxy,并始终使用Headless服务收集的端点列表来负载平衡客户端请求。
但是你能想象将这种逻辑添加到集群中部署的所有应用程序中吗?
如果您有现有的应用程序群,这听起来像是不可能完成的任务,但是还有另一种选择。
服务网格来拯救
您可能已经注意到,客户端负载平衡策略是非常标准的。 当应用程序启动时,它应该这么做:
- 从服务中检索IP地址列表
- 打开并维护一个连接池
- 通过添加和删除端点来定期刷新池
一旦它希望提出一次请求,它应使用预先定义的逻辑(如循环)选择一个可用的连接。
上面的步骤对WebSockets连接以及gRPC和AMQP有效。 您可以将该逻辑提取到一个单独的库中,并与所有应用共享。 你可以使用Istio或Linkerd这样的服务网格,而不是从头开始编写一个库。 服务网格用一个新进程来增强你的应用程序:
- 自动发现IP地址服务
- 检查连接,如WebSockets和gRPC
- 使用正确的协议来负载平衡请求
服务网格可以帮助您管理集群内部的流量,但是它们并不是完全轻量级的。
其他选项包括使用诸如Netflix Ribbon之类的库,诸如Envoy之类的可编程代理,或者只是忽略它。
如果你忽略它会发生什么?
您可以忽略负载平衡,并且仍然不会注意到任何更改,您应该考虑几种情况:
- 如果您的客户端数量多于服务器数量,那么问题应该是有限的。
- 假设您有五个客户端打开了到两个服务器的持久连接。
即使没有负载平衡,两个服务器也可能被利用。
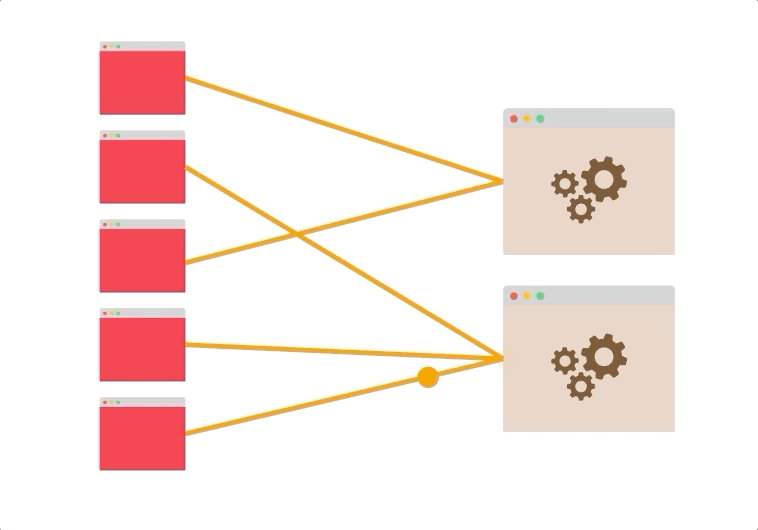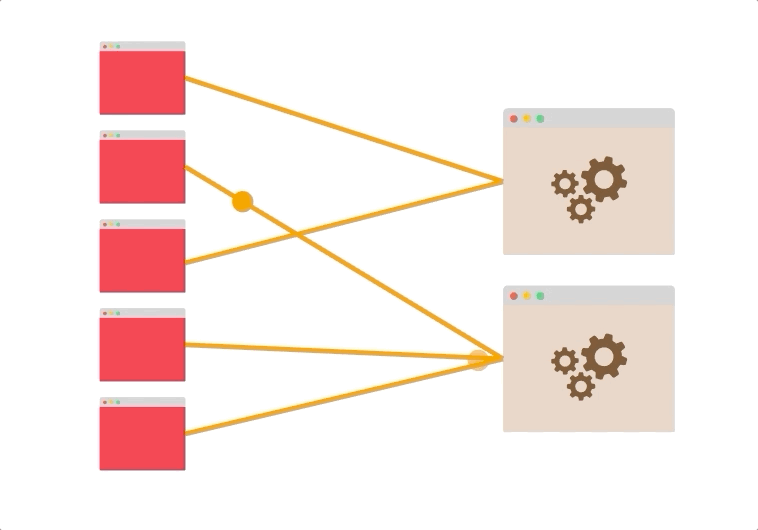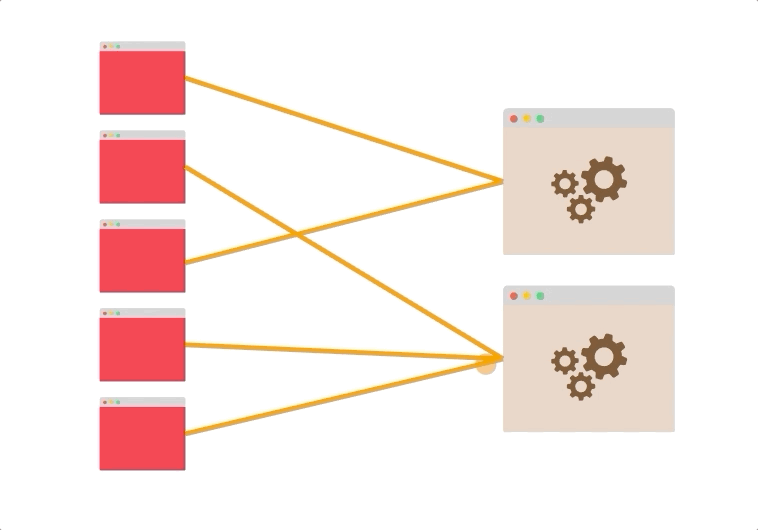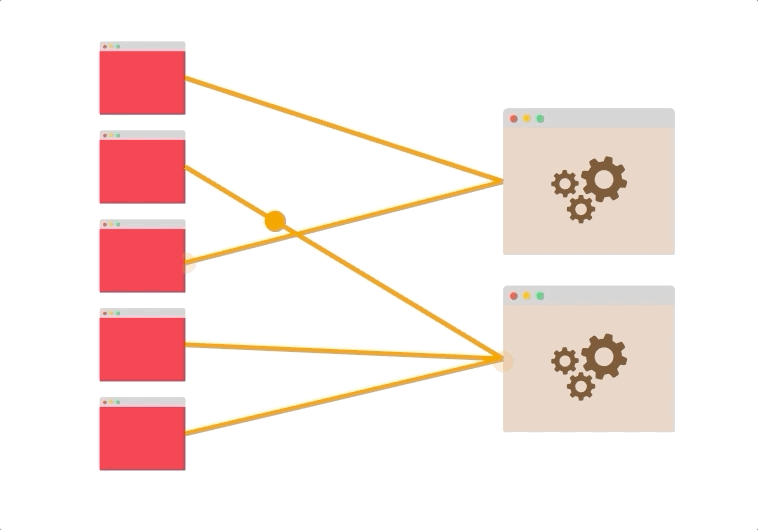
连接可能分布不均(也许最终有四个连接到同一台服务器),但是总体而言,很有可能同时使用了这两个服务器。
如果客户端更少,服务器更多,则可能有一些未充分利用的资源和潜在的瓶颈。
想象一下,有两个客户端和五个服务器,最多只能打开到两个服务器的两个持久连接,其余的服务器根本不使用。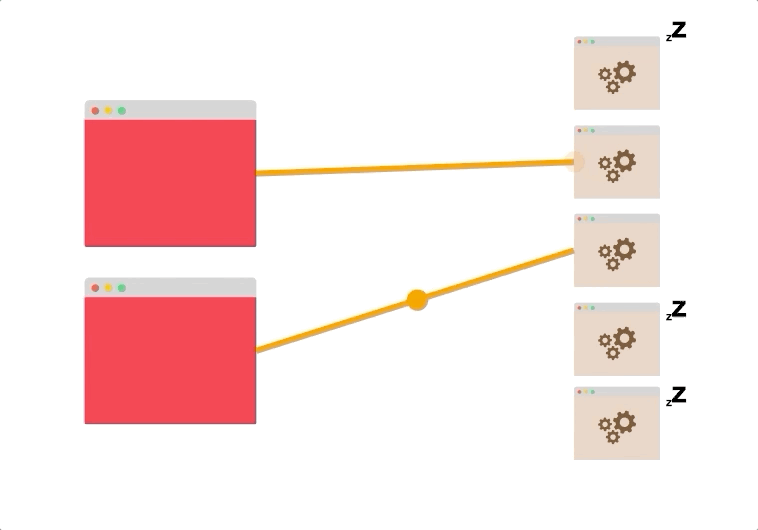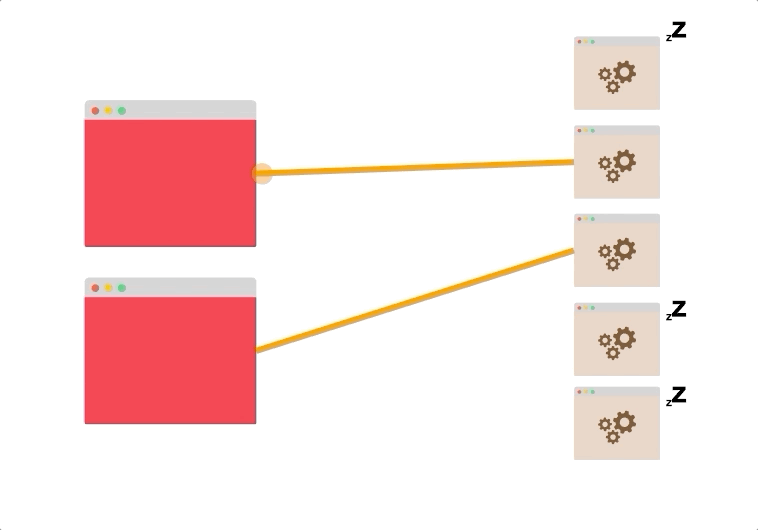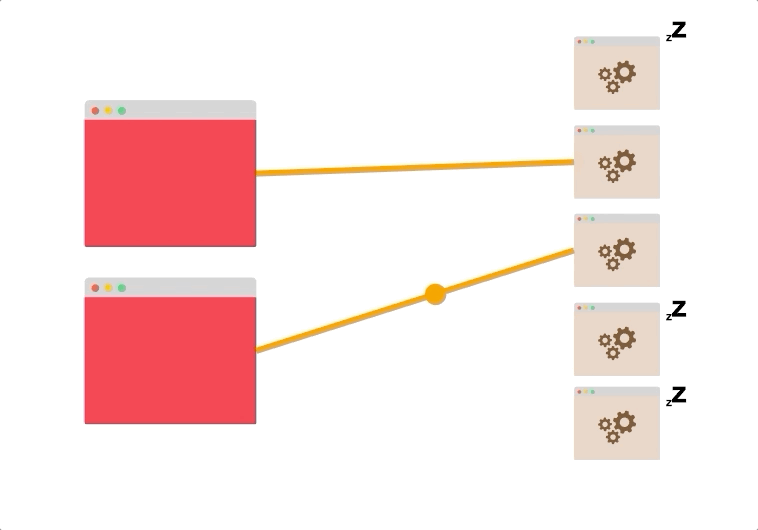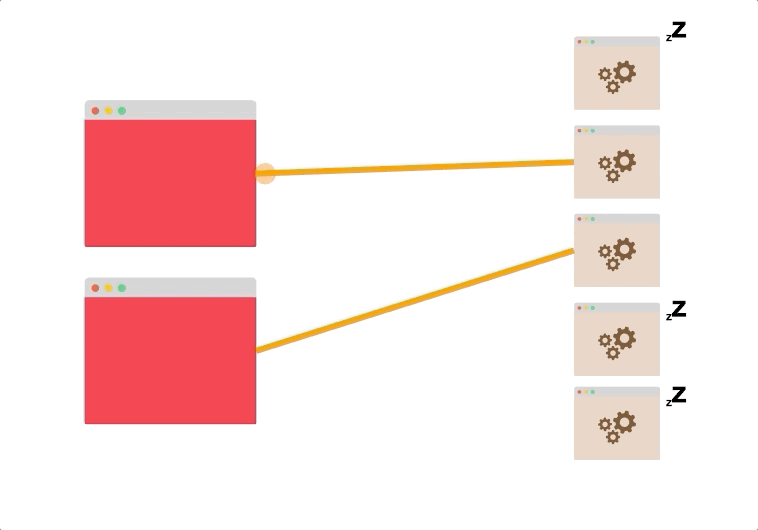
如果两个服务器不能处理客户端产生的流量,水平扩展将不会有帮助。
总结
Kubernetes Services旨在涵盖Web应用程序的最常见用途。
但是,一旦您开始使用使用持久性TCP连接的应用程序协议(例如数据库,gRPC或WebSockets),它们就会崩溃。
Kubernetes不提供任何内置机制来平衡长期存在的TCP连接的负载
原文路径:https://learnk8s.io/kubernetes-long-lived-connections