一 . 背景介绍
这篇文章是一片演讲笔记,这是Richard L. Hudson于2018.06.18在国际内存管理研讨会(ISMM)上的演讲。
理查德·哈德森(Rick)因其在内存管理方面的工作而闻名,其中包括发明了Train,Sapphire和Mississippi Delta算法以及GC堆栈映射,这些算法能够以静态类型的语言(例如Modula-3,Java)进行垃圾收集 ,C#和Go。 Rick目前是Google Go团队的成员,他致力于Go的垃圾回收和运行时问题。
Original URL : https://blog.golang.org/ismmkeynote
二. 演讲内容

在我们正式研究这些东西之前,我们首先需要展示一下GC在Go中看着像什么?

首先,Go程序有成千上万个堆栈,他们被Go调度器管理着并且总是在GC安全点被抢占。Go调度器将Go协程多路复用到系统线程上,希望每一个物理线程运行一个系统线程。我们通过复制堆栈和修改栈指针来管理栈及其大小。因为这些是本地操作所以很容易扩展。

接下来,我们需要讨论一个重要的内容,和传统C系统语言类似、Go也是一种“值定向”语言,而不是类似众多runtime管理型语言的“参考导向”语言。正如上面的例子展示了tar包中某一个类型如何在内存中布局存储,所有的字段均直接内嵌在Reader变量中。这使程序员可以在需要的时候更好的控制内存布局。可以把有关联值的字段进行临近分配,这样的策略有利于提高缓存的存储位置。
以值为导向有助于使用外部功能接口(有助于不同语言之间通信),Go语言和C/C++语言能够很快的FFI (语言交互接口 ) 操作,谷歌内部有大量可用的功能、但是他们使用C++编写的。Go语言迫不及待的实现这些功能,因此Go必须使用外部功能访问接口来实现这些功能。
基于这个设计上的决定导致Go运行时必须执行一些惊人的东西,这些可能是Go和其他带有GC的计算机语言最重要的不同之处。

Go语言当然会有指针的存在,但是事实上Go甚至可以有内部指针[ interior pointer ]。这些指针可以让数据的整体具有活性,而且他们很常见。

Go语言有一套完善的预编译系统,从而一个单独的二进制运行体文件就可以包含完整的运行时环境。
运行时也不需要JIT热点重新编译,这有优点也有缺点。首先,这种模式下程序执行的可重现性要容易很多,这使得编译器改进的步伐变得更快。
可悲的是,我们没有机会像使用JITed系统那样可以反馈优化。因此,静态预编译存在上述优缺点。

Go 提供了两个旋钮用来控制GC。第一个是GCPercent,这个旋钮基本上是用来调整要使用的CPU和内存的数量,默认值为100、代表一半的堆专用于活动内存、一半的堆用来分配。当然,你可以按照你需要的比例方向就行旋钮调整。
最大堆,这个属性目前尚未发布、但已经在内部使用和评估了,这个参数允许编程人员控制最大的堆使用空间。内存不足、内存溢出(OOM)、在Go语言上很难;暂时的内存使用高峰应该通过增加CPU成本来解决,不是通过终止程序。基本上,如果GC遇到了内存压力,它应该通知应用程序应该减轻负载。当一切恢复正常之后,GC会通知应用程序让其恢复到正常负载。最大堆特性还为调度提供更多的灵活性。运行时不必总是对可用的内存量有多大的幻想,而是可以将堆的大小调整为最大堆的大小。
这结束了我们对垃圾回收器很重要的Go片段的讨论。

现在让我们来谈谈Go语言运行时以及我们如何到达这里,如何达到自己所在的位置。这句话是演讲者想表达Go运行时GC是如何一路发展的。

2014年,毫无疑问、如果Go不能以某种方式解决GC延迟问题,则Go是不会成功的。
其他新语言也会遇到同样的问题。Rust之类的语言采用了不通的解决方式,但是这里我们将讲述Go所走的道路。
为什么延迟如此的重要?

延迟是个累积量,数学对此是不能完全解释的。
99%的隔离式GC延迟服务级别目标(SLO),例如 99% 的GC周期小于10ms,只是根本无法扩展。重要的是整个会话期间的延迟或一天中多次使用程序的延迟(这里表达的含义是:单次GC看着不重,但是无论对于单次长会话、还是长期运行的程序体,这会产生累计损害)。假设浏览一个网页的会话在一个会话中最终发出100个服务器请求,或者发出20个请求,并且一天中您有5个会话。 在这种情况下,只有37%的用户将在整个会话中获得一致的10毫秒以下体验。
正如我们所建议的那样,如果您希望这些用户中有99%的用户具有10ms以下的体验,则数学计算表明您确实需要定位4个9s或99.99%ile。
所以是2014年,杰夫·迪恩(Jeff Dean)发表了他的论文《The Tail at Scale》(规模的尾巴),进一步探讨了这一问题。 由于它对Google的向前发展和试图以Google规模扩展产生严重影响,因此在Google周围被广泛阅读。
我们称这个问题为9s暴政。

那么,我们是如何对抗这场“暴政”的呢?
我们在2014年做了不少事情。
如果您想要10个答案,请再输入几个,然后选择前10个,这些就是您在搜索页面上输入的答案。如果请求超过50%ile,则重新发出请求或将请求转发到另一台服务器。 如果GC将要运行,请拒绝新请求或将请求转发到另一台服务器,直到完成GC。 依此类推。这段文字讲述的是类似负载均衡模式降低系统整体的响应时间。
所有这些变通办法来自非常聪明的人,他们有非常实际的问题,但他们没有解决GC延迟的根本问题。 在Google规模上,我们必须解决根本问题。 为什么?

冗余无法扩展,冗余成本很高。 它花费了新的服务器场。
我们希望能够解决这个问题,并把它看作是一个改善服务器生态系统的机会,并在这个过程中拯救一些濒临灭绝的玉米田,让一些玉米粒有机会在7月4日达到膝盖高点,让玉米更好的生长。 (这段话的意思就是,希望通过节约服务器机房成本而保护环境。)

这就是2014年的SLO,是的,的确,我在打沙袋,在团队中我是新手,这对我来说是个新过程,我不想过分承诺。(这张PPT展示了2014年的GC能力)
此外,有关其他语言的GC延迟的演讲简直令人恐惧。

最初的计划是执行无读屏障的并发复制GC。 那是长期计划。 读屏障的开销存在很多不确定性,因此Go希望避免这些屏障。
但是在2014年短期,我们必须采取行动。我们必须将所有运行时和编译器都转换为Go。它们当时是用C编写的。没有更多的C语言了,因为C语言程序员不了解GC,但是对如何复制字符串有了一个很酷的想法,因此不再有很多错误。我们需要专注与GC延迟领域的技术方案或任何东西,但是这些东西带来的性能损失必须小于编译器提供的加速。因此我们受到了限制。基本上,我们花费一年在编译器性能上的改进,可以被GC并发协程消耗完。就是这样。 我们不能放慢Go程序的速度。 这在2014年将是站不住脚的。(艰苦的2014年)

因此,我们有所退缩。 我们不打算复制。
决定要做一个三色并发算法。在我职业生涯的早期,我和Eliot Moss做过日记证明,证明Dijkstra的算法可用于多个应用程序线程。我们还证明了可以解决STW问题,并且有证据证明可以解决这一问题。
我们还担心编译器的速度,即编译器生成的代码。 如果我们在大多数情况下都保持关闭写屏障,那么编译器的优化将受到最小的影响,并且编译器团队可以迅速前进。 Go还迫切需要在2015年取得短期成功。
因此,让我们看一下我们所做的一些事情。
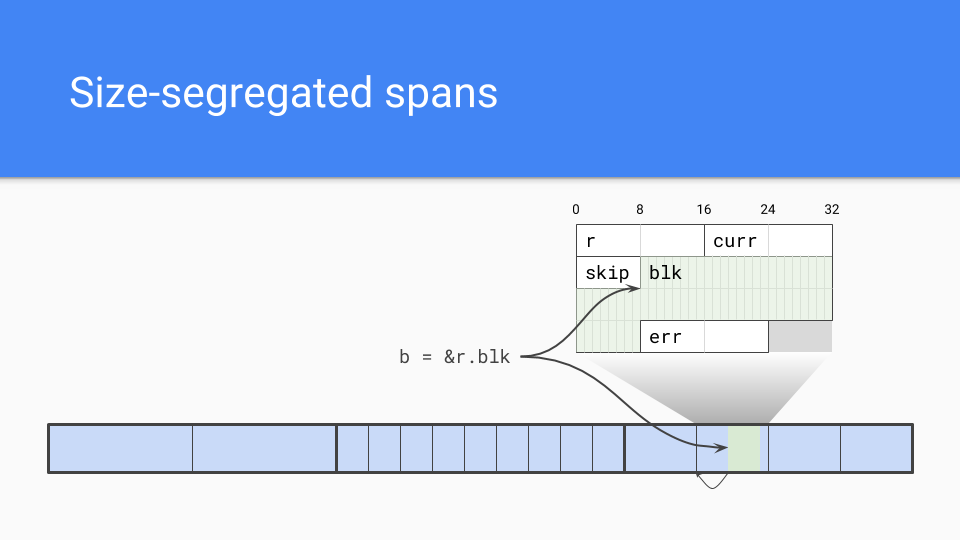
我们采用了大小分开的跨度。 内部指针是一个问题。 (这个也是很多优秀内存池内存分配的一种策略)
垃圾回收器需要高效的找到对象的内存起始点。如果知道跨度中对象的大小,则将其四舍五入为该大小,这将成为对象的开始。
当然,大小隔离的跨度还有其他一些优点。
低碎片化:使用C的经验,除了Google的TCMalloc和Hoard之外,我与Intel的可伸缩Malloc密切相关,这项工作使我们充满信心,碎片化对于不动的分配器不会成为问题。
内部结构:我们完全了解并拥有相关经验。 我们了解了如何进行大小隔离的跨度,我们了解了如何进行低竞争或零竞争的分配路径。
速度:非复制与我们无关,诚然,分配可能较慢,但仍为C顺序。它可能不及凹凸指针那么快,但这没关系。
我们还遇到了这个外部函数接口问题。如果我们不移动我们的对象,那么我们就不必处理可能遇到的长尾巴的错误,如果您有一个移动的收集器,当您试图锁定对象并在C和您正在使用的Go对象之间设置间接级别时。

下一个设计选择是放置对象元数据的位置。我们需要一些关于对象的信息,因为对象没有头部信息。标记位一直在对象临侧并用于标记和分配。每个字都有2位与之关联,以告诉您它是标量还是该字内的指针。它还对对象中是否有更多的指针进行了编码,因此我们可以早晚停止扫描对象。我们还有一个额外的位编码,可以用作额外的标记位或进行其他调试。这对运行这些东西和查找错误非常有价值。

那什么是写屏障呢?仅在GC期间打开写屏障。在其他时候,编译后的代码将加载一个全局的变量并查看它。由于GC通常处于关闭状态,因此硬件会正确推测在写屏障附近分支。当我们在GC中时,该变量是不同的,并且写屏障负责确保三色操作期间不会丢失任何可到达的对象。

该代码的另外一部分是 GC Pacer (GC 起搏器),这是Austin所做的一些伟大的工作。它基本上是用来确定何时最佳启动GC周期的反馈循环。如果系统处于稳定状态而不是相变,标记将在内存耗尽时结束。
但事实并非如此,因此Pacer还必须监视标记进度,并确保分配不会超过并发标记。
如果必要,Pacer 将减慢分配速度,同时加快标记速度。在较高的级别上,Pacer会停止Goroutine,它正在执行很多分配,并让它执行标记。工作量与Goroutine的分配成正比。这加快了垃圾收集器的速度,同时减慢了转换器的速度。
完成所有这些步骤后,Pacer将从该GC周期以及先前的GC周期中学到的知识,并计划何时启动下一个GC。
它所做的不止于此,但这是基本的方法。
数学绝对令人着迷,请我阅读设计文档。 如果您正在执行并发GC,那么您真的应该自己看一下这个数学,看看它是否与您的数学相同。 如果您有任何建议,请告诉我们。
Go 1.5 concurrent garbage collector pacing and Proposal: Separate soft and hard heap size goal

是的,我们取得了很多的成功。一个年轻的疯狂疯子Rick会拍下其中一些图表,并在我的肩膀上刺青它们,我为它们感到骄傲。

这一系列图像来自于Twitter的生产服务器,我们当然和这些生产服务器无关。布赖恩·哈特菲尔德(Brian Hatfield)进行了这些测量,并奇怪地在推特上发布了有关它们的信息。
在Y轴上,我们有毫秒级的GC延迟。 在X轴上,我们有时间。 每个点都是该GC期间世界暂停时间的停止点。
在2015年8月的第一个版本中,我们看到了从大约300-400毫秒下降到30或40毫秒的过程。 这很好,数量级很好。
我们将在这里将Y轴从0到400毫秒彻底更改为0到50毫秒。

这是6个月后。 改进主要是由于系统地消除了世界停止期间我们正在执行的所有O(heap)事情。从40毫秒降低到4或5,这是我们的第二个数量级改进。

我们必须清除其中的一些错误,并且在1.6.3的小版本中执行了此操作。这将延迟降低到10毫秒以下,这是我们的SLO。
我们将再次改变我们的Y轴,这次下降到0到5毫秒。

因此,现在是2016年8月,即第一次发布之后的一年。 再次,我们不断取消这些O(heap size) SWT处理过程。 我们在这里谈论的是18GB的堆。 我们有大得多的堆,并且当我们取消这些O(heap size) SWT暂停时,堆大小显然可以增加很多,而不会影响延迟。 因此,这对1.7有所帮助。

下一次发布是在2017年3月。我们有最后一个大的延迟下降,这是由于找出如何避免在GC周期结束时停止世界堆栈扫描。使我们进入亚毫秒范围。Y轴又将改变到1.5毫秒,我们看到第三个数量级的改善。

2017年8月版本几乎没有改善。 我们知道是什么导致了其余的停顿。这里的SLO耳语数字大约是100-200微秒,我们将朝着这个方向努力。如果你看到超过几百微秒的东西,那么我们真的想和你谈谈,看看它是否符合我们所知道的东西,或者它是否是我们没有研究过的新东西。无论如何,似乎很少有人要求降低延迟。重要的是要注意,这些延迟水平可能会发生在各种各样的非GC原因,俗话说“你不必比熊快,你只需要比你旁边的人快。”
在2月18日发布的1.10版本中并没有什么实质性的变化,只是一些清理和追踪角落的案例。

因此,新的一年和一个新的SLO这是我们的2018年SLO。
我们已将总CPU数降为GC周期中使用的CPU数。
堆仍然是2倍。
现在,我们的目标是每个GC周期停止世界暂停500微秒。也许这里有点沙袋(意思就是还有优化空间)。
分配将继续与GC协助成比例。
Pacer的状态已经好得多,因此我们希望在稳定状态下可以看到最少的GC辅助。
我们对此非常满意。再说一次,这不是SLA,而是SLO,所以这是一个目标,而不是协议,因为我们无法控制操作系统之类的东西。

这是好东西。让我们转移话题,开始讨论我们的失败。这些是我们的伤疤,有点像纹身,每个人都能看到。不管怎样,他们有更好的故事,让我们来做一些这样的故事。

我们的第一次尝试是做一个叫做面向请求的收集器(Request Oriented Collector)或ROC的东西。假设可以在这里看到。

那么这是什么意思?goroutine是看起来像Gophers的轻量级线程,因此这里有两个goroutine。他们分享一些东西,比如中间有两个蓝色的物体。它们有自己的私有堆栈和自己选择的私有对象。假设左边的人想分享绿色物体。

goroutine将它放在共享区域中,以便另一个goroutine可以访问它。他们可以将它挂接到共享堆中的某个对象上,或者将其分配给全局变量,而另一个Goroutine可以看到它。

最后,左边的Goroutine走到消亡的阶段,它即将悲伤地死去。

你知道你死后不能带着你的东西。你也不能拿走你的堆栈。此时堆栈实际上是空的,对象是不可到达的,所以您可以简单地回收它们。

这里重要的一点是,所有操作都是本地的,不需要任何全局同步。这与分代GC之类的方法有根本的不同,我们希望不必进行同步所获得的扩展足以让我们取得胜利。

该系统正在发生的另一个问题是写入障碍一直存在。 每当进行写操作时,我们都必须查看它是否正在将指向私有对象的指针写入公共对象。 如果是这样,我们将必须将引用对象公开,然后遍历可访问对象,以确保它们也公开。 那是一个非常昂贵的写障碍,可能导致许多高速缓存未命中。

也就是说,哇,我们取得了一些很好的成功。
这是一个端到端RPC基准测试。错误标记的Y轴从0到5毫秒(越低越好),反正就是这样。X轴基本上是镇流器或多大的核心数据库。
如你所见,如果你有ROC,并且没有太多的分享,事情实际上会发展得很好。如果没有ROC,就没那么好了。

但这还不够好,我们还必须确保ROC不会减慢系统的其他部分。在那个时候,有很多关于编译器的问题,我们不能减慢编译器的速度。不幸的是,这些编译器正是ROC不擅长的程序。我们看到了30、40、50%甚至更多的减速,这是不可接受的。Go的编译速度非常快,我们不能让它慢下来,至少不能慢这么多。

然后,我们去看了一些其他程序。这些是我们的性能基准。 我们拥有200或300个基准的资料库,而这些基准是编译器人员认为对他们进行改进和改进很重要的基准。这些根本没有被 GC人 员选中。这些数字一直都很糟糕,ROC 不会成为胜利者。

我们确实进行了扩展,但我们只有4到12个硬件线程系统,所以我们无法克服写屏障税(这是指写屏障的性能损耗)。也许在未来,当我们拥有128个核心系统时,Go会利用它们,ROC的可扩展性可能会是一个胜利。当这种情况发生时,我们可能会回来重新讨论这个问题,但就目前而言,ROC是一个失败的提议。

那我们接下来要做什么? 让我们尝试分代GC。 虽然历史有点陈旧,但是好东西。 ROC无法正常工作,因此让我们回到具有更多经验的方面。

我们不会放弃延迟,我们不会放弃不动的事实。所以我们需要一个非移动的分代GC。
我们可以这样做吗?是的,但是对于分代GC,写屏障总是存在的。当GC循环运行时,我们使用与今天相同的写屏障,但是当GC关闭时,我们使用一个快速的GC写屏障来缓冲指针,然后在缓冲区溢出时将缓冲区刷新到一个卡片标记表。
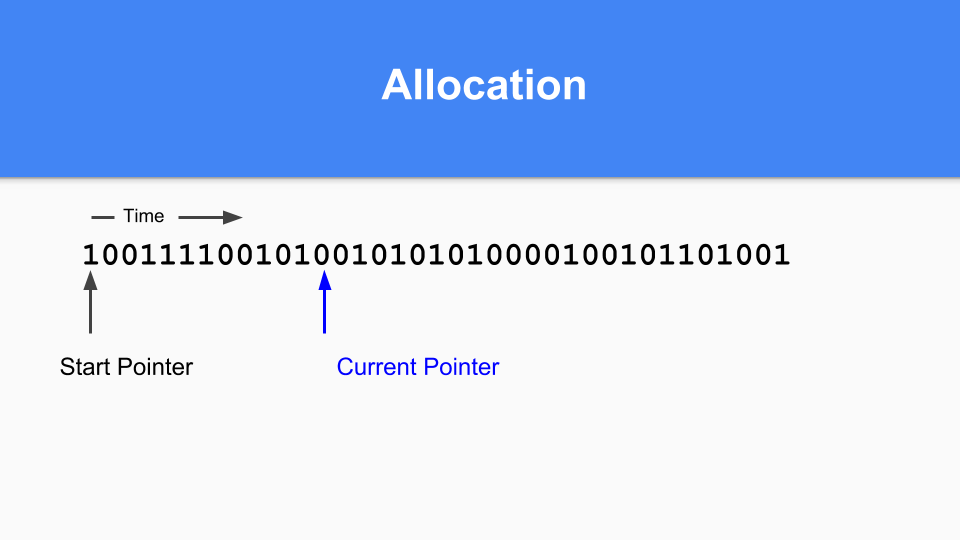
那么在不动的情况下,它是如何工作的呢?这是标记/分配图。基本上你维护一个当前指针。当你分配时,你寻找下一个0当你找到那个0时,你在那个空间中分配一个对象。

然后将当前指针更新到下一个0。

继续执行,直到需要生成GC的时候。您会注意到,如果标记/分配向量中有一个对象,那么该对象在最后一次GC时是活动的,因此它是成熟的。如果它是零,你到达它,你就知道它是年轻的。

那么你如何进行推广呢?如果你发现一个标记为1的对象指向一个标记为0的对象,那么你只需将该0设置为1就可以提升该引用。

必须执行可传递的遍历以确保升级所有可访问的对象。

当所有可到达的对象都被提升后,次要GC终止。

最后,要完成分代GC循环,只需将当前指针设置回向量的开头,然后就可以继续。在那个GC周期中没有达到所有的0,所以是空闲的,可以重用。众所周知,这被称为“粘性位”,是汉斯·勃姆(Hans Boehm)和他的同事们发明的。

那么性能如何? 对于大堆来说还不错。 这些是GC应该做得很好的基准。 一切都很好。

然后,我们在性能基准上对其进行了测试,结果进展不顺利。 那到底是怎么回事呢?

写屏障很快,但还不够快。此外,很难对其进行优化。例如,如果在分配对象和下一个安全点之间存在初始化写操作,则会发生写屏障清除。但我们不得不转向一个系统,在每个指令上都有一个GC安全点,这样就不会有任何写屏障,我们就可以排除它了。

我们还进行了逃逸分析,并且越来越好。还记得我们讲过的价值导向吗?我们将传递实际的值,而不是传递一个指向函数的指针。因为我们传递了一个值,所以逸出分析只需要进行程序内逸出分析,而不需要进行程序间分析。
当然,在指向本地对象的指针转义的情况下,对象将被堆分配。
这并不是说Go的世代假设 (generational hypothesis) 是不正确的,只是那些年轻的物体在堆栈上生老病死。其结果是,与其他托管运行时语言相比,分代收集的效率要低得多。

因此,抵制写障碍的这些力量开始聚集。今天,我们的编译器比2014年要好得多。逸出分析收集了许多这样的对象,并将它们放到堆栈上,而这些对象正是世代收集器本可以帮助处理的。我们开始创建工具来帮助用户找到转义的对象,如果转义的对象很小,他们可以更改代码并帮助编译器在堆栈上进行分配。
用户在采用面向价值的方法方面越来越聪明,指针的数量也在减少。数组和映射保存值,而不是指向结构的指针。一切都很好。(这个是Go GC优化的常用技巧点)
但这并不是Go语言写屏障不断前进的主要原因。

让我们看一下这张图。 这只是标记成本的分析图。每一行代表一个可能有标记成本的不同应用程序。假设你的标记成本是20%,这是相当高的,但这是可能的。红线是10%,仍然很高。下一行是5%这是现在写屏障的花费。如果堆大小翻倍会发生什么?这是右边的点。由于GC周期不那么频繁,标记阶段的累积成本大幅下降。写屏障的成本是恒定的,因此增加堆大小的成本将驱动在写屏障成本之下的标记成本。

这里是一个更常见的写屏障成本,为4%,我们可以看到,即使这样,我们也可以通过简单地增加堆大小来将标记屏障的成本降低到写屏障的成本之下。
分代GC的真正价值在于,在查看GC时间时,写屏障成本被忽略,因为它们被抹在了mutator上。这是分代GC的巨大优势,它极大地减少了整个GC周期的长STW时间,但不一定能提高吞吐量。Go没有停止世界的问题,所以它必须更密切地关注吞吐量问题,这就是我们所做的。

这是很多失败,伴随着失败的是食物和午餐。我一直在抱怨“如果不是因为写障碍,Gee不会很棒。”
与此同时,Austin刚刚花了一个小时的时间与一些在谷歌的HW GC人员进行了交谈,他说我们应该与他们进行交谈,并尝试找出获得硬件GC支持的方法,这可能会有所帮助。然后,我开始讲述一些战争故事,比如零填充高速缓存线路、可重新启动的原子序列,以及其他一些在我为一家大型硬件公司工作时没有成功的事情。当然,我们在一种叫Itanium的芯片里放了一些东西,但是我们无法把它们放到今天更受欢迎的芯片里。所以这个故事的寓意就是使用我们现有的硬件。(独特的GC 思维)
不管怎样,这让我们开始讨论,那疯狂的事情呢?

没有写屏障的卡片标记怎么办?结果奥斯汀有这些文件,他把所有疯狂的想法都写进了这些文件,但由于某种原因,他没有告诉我。我认为这是一种治疗方法。我以前对艾略特也是这样。新思想很容易被粉碎,人们需要保护它们,让它们变得更强大,然后再让它们进入这个世界。不管怎样,他提出了这个想法。
其思想是在每张卡中维护成熟指针的散列。如果指针被写入卡中,哈希值就会改变,卡就会被标记。这将用写屏障的成本换取哈希的成本。

但更重要的是它的硬件是一致的。
今天的现代架构有AES(高级加密标准)指令。其中一条指令可以进行加密级哈希,如果我们也遵循标准的加密策略,使用加密级哈希我们就不必担心冲突。所以哈希不会花费太多但我们必须加载我们要哈希的东西。幸运的是,我们正在按顺序遍历内存,因此我们获得了非常好的内存和缓存性能。如果你有一个DIMM,你按顺序地址,那么这是一个胜利,因为他们将比按随机地址更快。硬件预取器会起作用,这也会有帮助。不管怎样,我们有50年,60年的硬件设计来运行Fortran,运行C,运行SPECint基准测试。毫不奇怪,这样的结果是硬件运行速度很快。

我们进行了测量。这很好。这是大型堆的基准测试套件,应该不错。

然后我们说,它对于性能基准来说是什么样的呢?不太好,有几个异常值。但是现在我们已经将写障碍从总是在mutator中打开移到了作为GC周期的一部分运行。现在,关于是否要进行分代GC的决策被延迟到GC周期的开始。我们有更多的控制,因为我们本地化了card工作。现在我们有了工具,我们可以把它交给Pacer,它可以很好地动态地切断掉掉到右边的程序,并且不会从分代GC中受益。但这将是未来的胜利吗?我们必须知道或者至少考虑一下未来的硬件会是什么样子。

未来的内存是什么?

我们来看一下这个图。这是经典的摩尔定律图。Y轴上有一个对数刻度,表示单个芯片中晶体管的数量。x轴是1971年到2016年。我要指出的是,有些人在某些地方曾预言摩尔定律将不复存在。
十年前,Dennard scaling已经结束了频率改进。新的生产过程需要更长的时间来适应。所以他们现在不是2年而是4年或更多。所以很明显,我们正进入一个摩尔定律变慢的时代。
我们来看看红色圆圈里的筹码。这些是维持摩尔定律的最佳芯片。
它们是逻辑越来越简单的芯片,可以重复很多次。大量相同的内核、多个内存控制器和缓存、gpu、TPUs等等。
随着我们不断地简化和增加重复,我们最终会得到几根导线、一个晶体管和一个电容器。换句话说,DRAM存储单元。
换句话说,我们认为内存倍增比核心倍增更好。
Original graph at www.kurzweilai.net/ask-ray-the-future-of-moores-law.

让我们看看另一个关于DRAM的图。这些数字来自芝加哥大学最近的一篇博士论文。如果我们看这个,我们会发现摩尔定律是蓝线。红线是容量,它似乎遵循摩尔定律。奇怪的是,我看到了一张图表,它可以追溯到1939年,当时我们正在使用鼓式存储器,容量和摩尔定律一直在一起,所以这个图表已经持续了很长一段时间,肯定比这个房间里的任何人活得都长。
如果将此图与CPU频率或各种摩尔定律图进行比较,我们就会得出这样的结论:内存,或者至少是芯片容量,遵循摩尔定律的时间要比CPU长。带宽,也就是黄色的线,不仅与内存的频率有关还与芯片上的引脚数有关所以它没有跟上芯片的速度但也不是很差。
延时,也就是绿线,表现很差,不过我要指出,顺序访问的延时比随机访问的延时要好。
(数据来自“了解和改善基于DRAM的存储系统的延迟,部分满足电气和计算机工程哲学博士学位的要求Kevin K.Chang M.S.,电气和计算机工程,卡内基梅隆大学电气和计算机工程学士学位,卡内基梅隆大学卡内基梅隆大学匹兹堡分校,宾夕法尼亚州,2017年5月。请参见Kevin K. Chang的论文。引言中的原始图形并不是以我可以轻易在其上画出摩尔定律的形式出现的,所以我 将X轴更改为更均匀。)

我们去橡胶碰到路的地方。 这是DRAM的实际价格,从2005年到2016年总体上一直在下降。我选择2005年是因为那是在Dennard扩展结束并随之提高频率的时候。
如果您查看红色圆圈,那基本上是我们减少Go的GC延迟的工作正在进行的时间,我们发现在最初的几年中价格表现不错。 最近,情况不太好,因为需求超过供应,导致过去两年中价格上涨。 当然,晶体管并没有变得更大,在某些情况下芯片的容量已经增加,因此这是由市场力量驱动的。 RAMBUS和其他芯片制造商表示,展望未来,我们的下一个流程将在2019-2020年期间缩减。
除了指出定价是周期性的并且从长期来看供应趋向于满足需求之外,我将不再猜测存储器行业的全球市场力量。
从长远来看,我们相信内存价格的下降速度将比CPU价格快得多。
(Sources https://hblok.net/blog/ and https://hblok.net/storage_data/storage_memory_prices_2005-2017-12.png)

让我们看看另一条线。天哪,如果我们在这条线上就好了。这是SSD线路。它在保持低价格方面做得更好。这些芯片的材料物理比DRAM复杂得多。逻辑更复杂,不是每个单元一个晶体管,而是大约六个晶体管。
展望未来,DRAM和SSD之间将有一条界限,NVRAM(例如英特尔的3D XPoint和相变存储器(PCM))将得以生存。 在接下来的十年中,这种类型的内存的增加可用性可能会变得更加主流,这只会强化这样一种观念,即增加内存是为我们的服务器增加价值的廉价方法。
更重要的是,我们可以期待看到DRAM的其他竞争对手。我不会假装知道5年或10年后哪一个更受欢迎,但竞争将是激烈的,堆内存将更接近这里突出显示的蓝色SSD线。
All of this reinforces our decision to avoid always-on barriers in favor of increasing memory.
所有这些都强化了我们的决定,避免始终存在的屏障,有利于增加内存。(这个反应了Go GC 和硬件结合的思路,耐人寻味!)

那么,这一切对Go意味着什么?

当我们考虑来自用户的极端情况时,我们打算使运行时更加灵活和健壮。 希望可以减少调度程序的时间,并获得更好的确定性和公平性,但是我们不想牺牲任何性能。
我们也不打算增加GC API 控制接口。我们已经有将近10年的时间了,我们有两个旋钮,感觉是对的。没有重要到需要添加新标志的应用程序。
我们还将研究如何改进我们已经很好的逃逸分析并优化Go的面向价值的编程。不仅在编程方面,而且在我们为用户提供的工具方面。
从算法上讲,我们将重点关注设计空间中最小化屏障使用的部分,特别是那些一直处于开启状态的屏障。
最后,也是最重要的一点,我们希望能在未来5年甚至未来10年顺着摩尔定律倾向于RAM优先于CPU的趋势。
就是这样了。 谢谢。
