摘要
大规模互联网服务旨在出现意外故障时保持高可用性和高响应性。提供这种服务通常需要在大量系统上每秒钟监测和分析数千万次测量,一个特别有效的解决方案是在时间序列数据库(TSDB)中存储和查询这种测量。TSDB设计中的一个关键挑战是如何在效率、可伸缩性和可靠性之间取得平衡。在本文中,我们介绍Gorilla系统,脸书的内存TSDB。我们的见解是,监控系统的用户不太重视单个数据点,而是更重视综合分析,对于快速检测和诊断持续问题的根本原因而言,最新数据点比旧数据点更有价值。Gorilla优化了写入和读取的高可用性,即使在出现故障时也是如此,代价是可能会在写入路径上丢弃少量数据。为了提高查询效率,我们积极利用压缩技术,如增量时间戳和异或浮点值,将Gorilla的存储空间减少了10倍。这使我们能够将Gorilla的数据存储在内存中,与传统数据库(HBase)支持的时间序列数据相比,查询延迟减少了73倍,查询吞吐量提高了14倍。这种性能改进带来了新的监控和调试工具,比如时序关联搜索和更密集的可视化工具。Gorilla还可以优雅地处理从单个节点到整个区域的故障,几乎没有运营开销。
一、介绍
大规模互联网服务即使在出现意外故障的情况下也能保持高可用性和对用户的响应。随着这些服务发展到支持全球客户,它们已经从运行在数百台机器上的几个系统扩展到服务数以千计的个人用户系统运行在数千台机器上,通常跨越多个地理复制的数据中心。
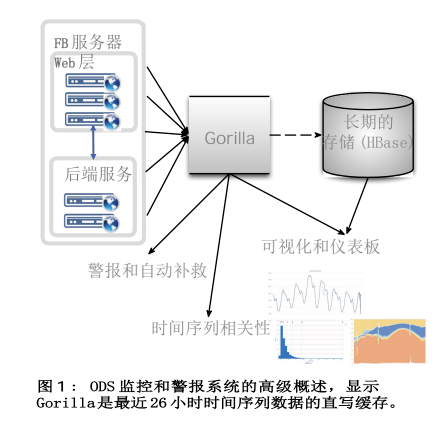
运行这些大规模服务的一个重要要求是准确监控底层系统的健康和性能,并在出现问题时快速识别和诊断问题。脸书使用时间序列数据库(TSDB)存储系统测量数据点,并在顶部提供快速查询功能。接下来,我们将指定监控和操作脸书需要满足的一些约束,然后描述Gorilla,这是我们新的内存TSDB,可以存储数千万个数据点(例如,CPU 负载、错误率、延迟等)。)并在几毫秒内响应对此数据的查询。
写占主导地位。我们对 TSDB 的主要要求是它应该始终可用于写入。由于我们有数百个公开数据项的系统,写入速率可能很容易超过每秒数千万个数据点。相比之下,读取速率通常要低几个数量级,因为它主要来自于观察“重要”时间序列数据的自动化系统、可视化系统或为希望诊断观察到问题的人类操作员提供仪表板。
状态转换。我们希望识别新软件发布中出现的问题、配置更改的意外副作用、网络中断以及导致重大状态转换的其他问题。因此,我们希望我们的TSDB支持短时间窗口内的细粒度聚合。在几十秒钟内显示状态转换的能力特别有价值,因为它允许自动化在问题变得广泛传播之前快速修复问题。
高可用性。即使网络分区或其他故障导致不同数据中心之间的连接断开,在任何给定数据中心内运行的系统都应该能够将数据写入本地TSDB机器,并且能够按需检索这些数据。
容错。我们希望将所有写入复制到多个区域,这样我们就可以在任何给定的数据中心或地理区域因灾难而丢失时幸存下来。
Gorilla是脸书的新TSDB,满足了这些限制。Gorilla用作进入监控系统的最新数据的直写缓存。我们的目标是确保大多数查询在几十毫秒内运行。Gorilla 的设计理念是,监控系统的用户不太重视单个数据点,而是更重视综合分析。此外,这些系统不存储任何用户数据,因此传统的 ACID保证不是TSDB的核心要求。 但是,高比例的写入必须始终成功,即使面临可能导致整个数据中心无法访问的灾难。此外,最近的数据点比旧的数据点具有更高的价值,因为直觉上,对于运营工程师来说,知道特定系统或服务现在是否被破坏比知道它是否在一个小时前被破坏更有价值,Gorilla 进行了优化,即使在出现故障的情况下也能保持高度的读写可用性,代价是可能会丢失少量数据写入路径。
高数据插入率、总数据量、实时聚合和可靠性要求带来了挑战。我们依次解决了这些问题。为了解决第一个要求,我们分析了 TSDB 操作数据存储(ODS),这是一个在脸书广泛使用的老的监控系统。我们注意到,对ODS的所有查询中,至少有85%是针对过去26小时内收集的数据。进一步的分析使我们能够确定,如果我们能够用内存中的数据库替换基于磁盘的数据库,我们可能能够为我们的用户提供最好的服务。此外,通过将这个内存中的数据库视为持久的基于磁盘的存储的缓存,我们可以实现具有基于磁盘的数据库的持久性的内存中系统的插入速度。
截至2015年春天,脸书的监控系统生成了超过20亿个独特的时间序列计数器,每秒钟增加约1200万个数据点。这代表每天超过1万亿个点。在每点16字节的情况下,产生的16TBRAM对于实际部署来说太耗费资源了。我们通过重新利用现有的基于XOR的浮点压缩方案来解决这一问题,使其以流的方式工作,从而允许我们将时间序列压缩到平均每点1.37字节,大小减少了12倍。
我们通过在不同的数据中心区域运行多个Gorilla实例并向每个实例传输数据流来满足可靠性要求,而不试图保证一致性。读取查询指向最近的可用Gorilla实例。请注意,这种设计利用了我们的观察,即在不影响数据聚合的情况下,单个数据点可能会丢失,除非Gorilla实例之间存在显著差异。Gorilla目前正在脸书的生产中运行,工程师们每天将其用于实时灭火和调试,并与Hive[27]和Scuba[3]等其他监控和分析系统结合使用,以检测和诊断问题。
二、背景和要求
2.1 操作数据存储
脸书的大型基础设施由分布在多个数据中心的数百个系统组成,如果没有能够跟踪其运行状况和性能的监控系统,运营和管理这些基础设施将会非常困难。业务数据储存库是脸书监测系统的一个重要部分。ODS由一个时间序列数据库(TSDB)、一个查询服务以及一个探测和警报系统组成。ODS的TSDB 构建在 HBase存储系统之上,如[26]中所述。图1显示了ODS组织方式的高级视图。来自运行在脸书主机上的服务的时间序列数据由ODS写入服务收集并写入 HBase。
ODS时间序列数据有两个消费者。第一个消费者是依赖制图系统的工程师,该系统从ODS生成图形和其他时间序列数据的直观表示,用于交互式分析。第二个消费者是我们的自动警报系统,该系统从 ODS读取计数器,将它们与健康、性能和诊断指标的预设阈值进行比较,并向oncall工程师和自动补救系统发出警报。
2.1.1 监控系统读取性能问题
2013 年初,脸书的监控团队意识到其HBase时序存储系统无法扩展处理未来的读取负载。虽然交互式图表的平均读取延迟是可以接受的,但是P90的查询时间增加到了几秒钟,阻碍了我们的自动化。此外,用户正在自我审查他们的用户年龄,因为即使是几千个时间序列的中等规模查询的交互式分析也需要几十秒钟才能执行。在稀疏数据集上执行的较大查询会超时,因为HBase数据存储被调整为优先写入。虽然我们基于HBase的TSDB效率低下,但我们很快就对存储系统进行了大规模更换,因为 ODS的HBase存储拥有大约2PB 的数据[5]。脸书的数据仓库解决方案Hive也不合适,因为它的查询延迟比ODS 高几个数量级,而查询延迟和效率是我们主要关心的问题[27]。
接下来,我们将注意力转向内存缓存。ODS已经使用了一个简单的通读缓存,但它主要是针对多个仪表板共享相同时间序列的图表系统。一个特别困难的场景是当仪表板查询最近的数据点,在缓存中错过,然后发出请求直接发送到 HBase 数据存储。我们还考虑了基于独立Memcache[20]的直写缓存,但拒绝了它,因为向现有时间序列添加新数据需要一个读/写周期,从而导致Memcache服务器的流量非常高。我们需要更有效的解决方案。
2.2 Gorilla要求
考虑到这些因素,我们确定了新服务的以下要求:
- 由一个字符串键标识的20亿个唯一的时间序列。
- 每分钟增加7亿个数据点(时间戳和值)。
- 存储数据26小时。
- 峰值时每秒超过40,000次查询。
- 读取在不到一毫秒的时间内成功。
- 支持15秒粒度的时间序列(每个时间序列每分钟 4 个点)。
- 两个内存中、不在同一位置的副本(用于灾难恢复容量)。
- 即使单个服务器崩溃,也始终提供读取服务。
- 能够快速扫描所有内存中的数据。
- 支持每年至少2倍的增长。
在第3节与其他 TSDB 系统进行简单比较后,我们在第4节详细介绍Gorilla的实现,首先在第4.1 节讨论其新的时间戳和数据值压缩方案。然后,我们将在第 4.4 节中描述Gorilla如何在单节点故障和区域性灾难的情况下保持高可用性。我们将在第5节描述Gorilla如何启用新工具。最后,我们在第6节描述了我们开发和部署Gorilla的经验。
三、与 TSDB 系统的比较
有许多出版物详细介绍了数据挖掘技术,以有效地搜索、分类和聚类大量的时间序列数据[8,23,24]。这些系统展示了检查时间序列数据的许多用途,从聚类和分类[8,23]到异常检测[10,16] 到索引时间序列[9,12,24]。然而,很少有例子详细说明能够实时收集和存储大量时间序列数据的系统。Gorilla的设计侧重于对生产系统进行可靠的实时监控,与其他TSDB相比非常突出。Gorilla占据了一个有趣的设计空间,在面对优先于任何旧数据可用性的故障时,可用于读取和写入。
由于 Gorilla 从一开始就被设计为将所有数据存储在内存中,因此它的内存结构也不同于现有TSDB。但是,如果将Gorilla视为另一个磁盘上TSDB之前的时间序列数据内存存储的中间存储,那么Gorilla 可以用作任何 TSDB 的直写缓存(相对简单的修改)。Gorilla对摄取速度和水平扩展的关注与现有解决方案相似。
3.1 OpenTSDB
OpenTSDB基于HBase[28],非常接近我们用于长期数据的ODS HBase存储层。这两个系统依赖于相似的表结构,并且在优化和水平可伸缩性方面得出了相似的结论[26,28]。然而,我们发现支持构建高级监控工具所需的查询量需要比基于磁盘的存储所能支持的更快的查询。
与OpenTSDB不同,ODS HBase层确实为较旧的数据进行时间累积聚合以节省空间。这导致较旧的存档数据与ODS中较新的数据相比具有较低的时间粒度,而OpenTSDB将永远保留全分辨率数据。我们发现,更便宜的长时间查询和空间节省是值得的精度损失。
OpenTSDB 还有一个更丰富的数据模型来识别时间序列。每个时间序列由一组任意的键值对标识,称为标签 [28]。Gorilla使用单个字符串键识别时间序列,并依靠更高级的工具来提取和识别时间序列元数据。
3.2 Whisper(Graphite)
Graphite将时间序列数据以Whisper格式存储在本地磁盘上,这是一种循环数据库 (RRD) 风格的数据库[1]。这种文件格式要求时间序列数据以固定的时间间隔进行时间标记,并且不支持时间序列中的抖动。虽然Gorilla在数据以固定时间间隔标记时工作效率更高,但它可以处理任意和不断变化的时间间隔。使用Whisper,每个时间序列都存储在一个单独的文件中,新的样本会在一定时间后覆盖旧的样本[1]。Gorilla以类似的方式工作,只在内存中保存最近一天的数据。然而,由于其专注于磁盘存储,使用Graphite/Whisper的查询延迟不够快,无法满足Gorilla的要求。
3.3 InfluxDB
InfluxDB是一个新的开源时间序列数据库,其数据模型比OpenTSDB更加丰富。时间序列中的每个事件都可以有一整套元数据。虽然这种灵活性确实允许使用丰富的数据,但它必然会比只在数据库中存储时间序列的方案使用更多的磁盘[2]。InfluxDB还包含将其构建为分布式存储集群的代码,允许用户水平扩展,而无需管理HBase/Hadoop集群的开销[2]。在脸书,我们已经有专门的团队来支持我们的HBase安装,因此将它用于ODS并不涉及大量的额外资源投资。与其他系统一样,InfluxDB将数据保存在磁盘上,这导致查询速度比数据保存在内存中慢。
四、Gorilla架构
Gorilla 是一种内存TSDB,用作直写缓存,用于监控写入HBase数据存储的数据。Gorilla中存储的监控数据是一个简单的三元组,包括一个字符串键、一个64位时间戳整数和一个双精度浮点值。Gorilla采用了一种新的时间序列压缩算法,允许我们将每个序列从16字节压缩到平均1.37字节,大小减少了12倍。此外,我们还设计了Gorilla的内存数据结构,以支持高效扫描所有数据,同时保持对各个时间序列的时间查找。
监控数据中指定的关键字用于唯一标识时间序列。通过基于这些唯一的字符串键对所有监控数据进行分片,每个时间序列数据集都可以映射到单个Gorilla主机。因此,我们可以通过简单地添加新主机和调整分片功能来将新的时间序列数据映射到扩展的主机集,从而扩展Gorilla。当Gorilla在18个月前投入生产时,我们在过去26小时内插入的所有时间序列数据的数据集可以放入1.3TB的RAM中,均匀分布在20台机器上。从那时起,由于数据增长,我们不得不将集群的规模扩大一倍,现在每个Gorilla集群中有80台机器在运行。由于无共享架构和对水平可扩展性的关注,这一过程非常简单。
Gorilla通过将每个时间序列值写入不同地理区域的两台主机,可以容忍单节点故障、网络中断和整个数据中心故障。检测到故障时,所有读取查询都故障转移到备用区域,确保用户不会遇到任何中断。
4.1 时间序列压缩
在评估构建内存时间序列数据库的可行性时,我们考虑了几种现有的压缩方案来减少存储开销。我们确定了仅适用于整数数据的技术,这些数据不符合我们存储双精度浮点值的要求。其他技术在完整的数据集上运行,但不支持像Gorilla [7,13]中存储的数据流上的压缩。我们还确定了数据挖掘中使用的有损时间序列近似技术,以使问题集更容易适应内存[15,11],但是Gorilla专注于保持数据的全分辨率表示。
我们的工作受到科学计算中得出的浮点数据压缩方案的启发。这个方案利用与先前值的 XOR 比较来生成增量编码 [25, 17]。
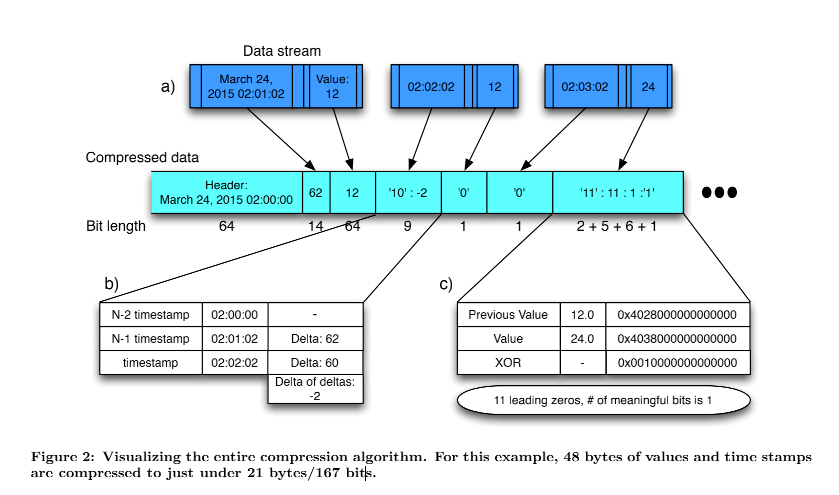
Gorilla压缩一个时间序列内的数据点,而不跨时间序列使用额外的压缩。每个数据点是一对 64位值,代表当时的时间戳和值。使用关于先前值的信息分别压缩时间戳和值。整个压缩方案如图2所示,显示了时间戳和值如何在压缩块中交错。
图2.a将时间序列数据显示为由成对的测量值(值)和时间戳组成的数据流。Gorilla将数据流压缩成块,按时间划分。在具有对齐时间戳(在本例中,从凌晨2点开始)的简单报头之后,并以压缩程度较低的格式存储第一个值,图2.b显示了使用delta-of-delta压缩来压缩时间戳,在第 4.1.1节中有更详细的描述。如图所示2.b delta 的时间戳delta是2。它存储在一个两位的头中(“10”),值存储在7位中,总大小只有9位。 图2.c显示了使用XOR压缩来压缩浮点值,在4.1.2 节中有更详细的描述。通过将浮点值与前一个值进行XOR运算,我们发现XOR运算中只有一个有意义的位。然后用一个两位的标题(“11”)对其进行编码,编码为有 11个前导零、一个有意义的位和实际值(“1”),这总共存储在 14 位中。

4.1.1 压缩时间戳
我们分析了存储在ODS中的时间序列数据,以便优化在Gorilla中实现的压缩方案。我们注意到,ODS的绝大多数数据点都是以固定的时间间隔到达的。例如,时间序列通常每60秒记录一个点。有时,该点可能有一个早或晚 1 秒的时间戳,但该窗口通常是受约束的。
我们不是存储完整的时间戳,而是存储增量的有效增量。如果时间序列中后续数据点的时间戳之间的差值分别是 60、60、59 和 61,则通过从给出 0、-1 和2的前一个时间戳值中减去当前时间戳值来计算差值的差值。图2显示了这种工作方式的一个例子。
接下来,我们通过以下算法使用可变长度编码对增量进行编码:

通过从生产系统中抽取一组实时序列来选择不同范围的界限
并且选择给出最佳压缩比的那些。时间序列可能会丢失数据点,但现有的数据点可能会以固定的时间间隔到达。例如,如果有一个数据点缺失,增量可能是 60、60、121 和59。增量的增量将是 0、61 和-62。61 和-62 都在最小范围内,可以用更少的位来编码这些值。下一个最小的范围[-255,256]很有用,因为每 4 分钟就会出现大量的数据点,而丢失的一个数据点仍然使用该范围。 图3显示了Gorilla中时间戳压缩的结果。我们发现大约 96%的时间标记可以被压缩成一个比特。
4.1.2 压缩值
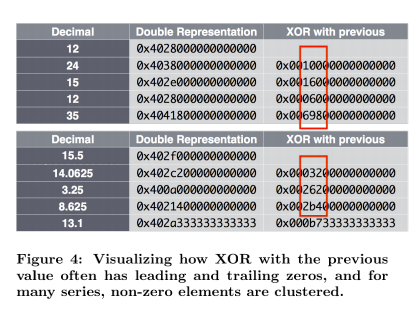
除了时间戳压缩,Gorilla还压缩数据值。Gorilla将其元组中的value元素限制为双浮点类型。我们使用类似于现有浮点压缩算法的压缩方案,如[17]和[25]中所述。 通过分析ODS数据,我们发现大多数时间序列中的值与其相邻数据点相比没有显著变化。此外,许多数据源只将整数存储到ODS中。这使得我们能够将[25]中昂贵的预测方案调整为更简单的实施方案,该方案仅将当前值与先前值进行比较。如果数值很接近,则尾数的符号、指数和前几位是相同的。我们利用这一点来计算当前值和先前值的简单 XOR,而不是采用 delta 编码方案。
然后,我们使用以下可变长度编码方案对这些异或值进行编码:
- 第一个值存储时没有压缩
- 如果与前一个异或为零 (相同值 ),存储单个“0”位
- 当XOR为非零值时,计算XOR中前导零和尾随零的数量,存储位“1”,后跟(a)或(b):
- (控制位‘0’)如果有意义位的块落在先前有意义位的块内,即至少有与先前值一样多的前导零和尾随零,使用块位置信息,只存储有意义的异或值。
- (控制位“1”)在接下来的5位中存储前导零的长度,然后在接下来的6位中存储有意义的异或值的长度,最后存储异或值的有效位。
整个压缩方案如图2所示,图2描述了我们的XOR编码如何高效地存储时间序列中的值。
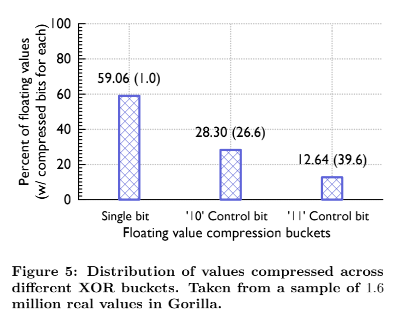
图5显示了Gorilla中实际值的分布。大约59%的值被压缩为一位,因为当前值和先前值是相同的。大约30%的值用控制位“10”压缩(情况b),平均压缩大小为26.6位。剩余的19%用控制位“11”压缩,平均大小为36.9位,因为编码前导零位和有意义位的长度需要额外的13位开销。这种压缩算法使用先前的浮点值和先前的异或值。这导致了额外的压缩因子,因为异或值序列通常具有非常相似的前导零和尾随零数量,如图4所示。整数值压缩得特别好,因为XOR 运算后的1位的位置对于整个时间序列来说通常是相同的,这意味着大多数值具有相同数量的尾随零。
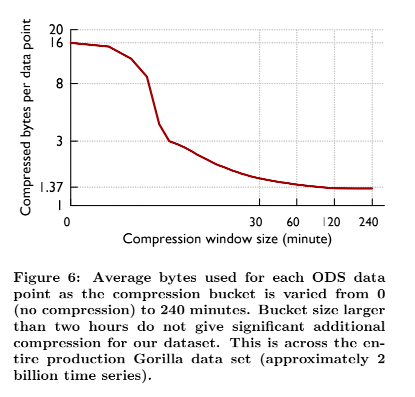
我们的编码方案中固有的一个折衷是压缩算法运行的时间跨度。在更长的时间周期内使用相同的编码方案允许我们获得更好的压缩比。然而,希望在短时间内读取数据的查询可能需要在解码数据上花费额外的计算资源。图 6 显示了当我们改变块大小时,存储在ODS中的时间序列的平均压缩率。可以看出,超过两个小时的块对压缩大小的回报是递减的。两小时的数据块允许我们实现的压缩比为每个数据点 1.37 字节。
4.2 内存中的数据结构
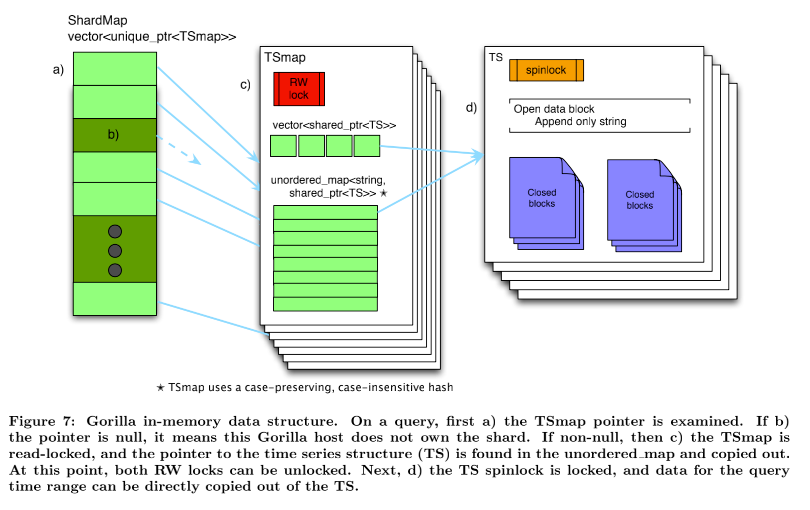
Gorilla实现中的主要数据结构是时间序列映射(TSmap)。图7概述了这种数据结构。TSmap由一个指向时间序列的 C++标准库共享指针vector和一个从时间序列名称到时间序列名称的不区分大小写、保留大小写的映射组成。vector允许对所有数据进行高效的分页扫描,而map允许对特定时间序列进行常量时间查找。为了实现快速读取的设计要求,同时仍然允许高效的数据扫描,恒定时间查找是必要的。
C++共享指针的使用使得扫描能够在几微秒内复制向量 (或其页面),避免了会影响传入数据流的冗长的关键部分。在删除时间序列时,向量条目被删除,并且索引被放置在空闲池中,该空闲池在创建新的时间序列时被重用。对内存的一部分进行逻辑删除会将它标记为“死的”,并准备好被重用,而实际上并没有将它释放给底层系统。并发性是通过保护映射和向量访问的单个读写旋转锁以及每个时间序列上的1字节旋转锁实现的。由于每个单独的时间序列都具有相对较低的写入吞吐量,因此自旋锁具有非常低的读取和写入之间的争用。
如图7所示,碎片标识符(shardId)到TSmap的映射(名为ShardMap)由指向TSmap的指针向量维护。使用TSmap中相同的不区分大小写的散列将时间序列名称映射到碎片,将其映射到[0,NumberOfShards)之间的ID。因为系统中碎片的总数是恒定的,并且数量在几千以内,所以在ShardMap中存储空指针的额外开销可以忽略不计。像TSmaps一样,对ShardMap的并发访问是通过读写旋转锁来管理的。
由于数据已经由shard进行了分区,单个映射仍然足够小(大约一百万个条目),C++标准库无序映射具有足够的性能,并且没有锁争用问题。
时间序列数据结构由两小时前的数据的一系列封闭块和保存最新数据的单个开放数据块组成。开放数据块是一个只附加的字符串,新的、压缩的时间戳和值被附加到该字符串。由于每个数据块保存两个小时的压缩数据,因此打开的数据块一旦填满就会关闭。一旦一个块被关闭,它就永远不会改变,直到它被从内存中删除。 关闭时,会将一个块复制到从大型片分配的内存中,以减少碎片。虽然开放块经常随着大小的变化而重新分配,但我们发现复制过程减少了Gorilla中的整体碎片。
通过将可能包含所查询时间范围内的数据的数据块直接复制到输出远程过程调用结构中来读出数据。整个数据块 被返回给客户机,剩下的解压缩步骤在Gorilla之外完成。
4.3 在磁盘结构上
Gorilla 的一个目标是在单主机故障中存活。Gorilla通将数据存储在GlusterFS中来实现持久性,GlusterFS是一个符合POSIX的分布式文件系统[4],具有3倍复制能力。HDFS或其他分布式文件系统就足够了。我们也考虑过单主机数据库,如MySQL和RocksDB,但决定不考虑这些,因为我们的持久性用例不需要数据库查询语言。
Gorilla主机将拥有多个数据分片,并且每个分片维护一个目录。每个目录包含四种类型的文件:密钥列表、仅追加日志、完整块文件和检查点文件。
键列表只是时间序列字符串键的映射整数标识符。这个整数标识符是内存中向量的索引。新的密钥被添加到当前密钥列表中,Gorilla定期扫描每个碎片的所有密钥,以便重写文件。
当数据点传输到Gorilla时,它们存储在一个日志文件中。时间戳和值使用第4.1节中描述的格式进行压缩。但是,每个分片只有一个只追加日志,所以分片中的值在时间序列上是交错的。这种与内存中编码的不同意味着每个压缩的时间戳-值对也用它的32位整数ID来标记,这大大增加了每个分片日志文件的存储开销。
Gorilla不提供ACID保证,因此,日志文件不是预写日志。在刷新之前,数据被缓冲到64kB,通常包含一秒或两秒的数据。虽然缓冲区在干净关闭时被刷新,但是崩溃可能会导致少量数据的丢失。我们发现这种权衡值得数据损失,因为与传统的预写日志相比,它允许将更高的数据速率推送到磁盘,并提供更高的写入可用性。
每两个小时,Gorilla将压缩的块数据复制到磁盘,因为这种格式比日志文件小得多。每两个小时的数据就有一个完整的块文件。它有两个部分:一组连续的64kB数据块,当它们出现在内存中时直接复制,以及一个<时序ID,数据块指针>对的列表。一旦块文件完成,Gorilla就会触及检查点文件并删除相应的日志。检查点文件用于标记何时将完整的块文件刷新到磁盘。如果块文件在进程崩溃时没有成功刷新到磁盘,则当新进程启动时,检查点文件将不存在,因此新进程知道它不能信任块文件,而是只从日志文件中读取。
4.4 处理故障
对于容错,我们选择优先容忍单个节点、可观察到的停机时间为零的大规模临时故障,以及局部故障(如整个区域的网络中断)。我们这样做是因为单节点故障经常发生,大规模的局部故障成为脸书规模的一个问题,以允许在自然(或人为)灾害下运行的能力。还有一个额外的好处是,人们可以将滚动软件升级建模为一组受控的单节点故障,因此针对这种情况进行优化意味着轻松和频繁的代码推送。对于所有其他故障,我们选择的折衷方案是,当它们确实导致数据丢失时,将使更新数据的可用性优先于旧数据。这是因为我们可以依靠现有的HBase TSDB 系统来处理历史数据查询,而检测时间序列中水平变化的自动化系统对部分数据仍然有用,只要有最新的数据。
Gorilla通过在独立的数据中心区域维护两个完全独立的实例,确保其对数据中心故障或网络分区保持高可用性。在写入时,数据流向每个Gorilla实例,不试图保证一致性。这使得大规模故障易于处理。当整个区域出现故障时,查询将定向到另一个区域,直到第一个区域备份了26小时。这对于处理大规模灾难事件非常重要,无论是真实的还是模拟的[21]。例如,当区域A中的Gorilla实例完全失败时,对该区域的读取和写入也将失败。将对健康区域b中的Gorilla 实例透明地重试读取失败。如果事件持续足够长的时间(超过一分钟), 将从区域 A 中丢弃数据,并且不会重试请求。发生这种情况时,可以关闭区域 A 的所有读取,直到群集运行状况良好至少26小时。这种补救可以手动或自动执行。
在每个区域内,基于Paxos的[6,14]系统称为ShardManager,它为节点分配碎片。当一个节点出现故障时,ShardManager会将其碎片分布到集群中的其他节点上。在碎片移动期间,写客户端缓冲它们的传入数据。缓冲区的大小可容纳1分钟的数据,超过1分钟的点将被丢弃,以便为较新的数据腾出空间。我们发现,在大多数情况下,这个时间段足以允许碎片重新分配, 但是对于长时间的中断,它优先考虑最近的数据,因为更近的数据直观上对驱动自动检测系统更有用。当区域A中的Gorilla主机α因任何原因崩溃或关闭时,写入会缓冲至少1分钟,因为Gorilla集群会尝试恢复主机。如果集群的其余部分是健康的,碎片移动会在30秒或更短的时间内发生,不会导致数据丢失。如果移动发生得不够快,可以通过手动或自动过程将读取指向区域B中的Gorilla实例。
当碎片被添加到主机时,它将从GlusterFS中读取所有数据。这些碎片可能在重新启动之前由同一个主机或另一个主机拥有。主机可以在大约5分钟内从GlusterFS读取和处理它需要的所有数据,以实现完全功能。因为碎片的数量系统和存储的总数据,每个碎片代表大约16GB的磁盘存储。这可以在几分钟内从GlusterFS中读取,因为文件分布在几个物理主机上。当主机读取数据时,它将接受新的传入数据点,并将它们放入队列中,以便在尽可能早的时间进行处理。当碎片被重新分配时,客户端立即通过写入新节点来耗尽其缓冲区。回到区域A崩溃示例中的Gorilla主机α:当α崩溃时,碎片被重新分配给同一个Gorilla实例中的主机β。一旦为主机 β分配了碎片,它就开始接受流写入,因此传输中的数据不会丢失。如果Gorilla host α以更可控的方式停机,它会在退出之前将所有数据刷新到磁盘,因此软件升级不会丢失任何数据。
在我们的示例中,如果主机α在成功将其缓冲区刷新到磁盘之前崩溃,数据将会丢失。实际上,这种情况很少发生,实际上只有几秒钟的数据丢失。我们做出这种折衷,以接受更高的写入吞吐量,并允许在停机后更快地接受更多的最新写入。此外,我们监控这种情况,并能够将读数指向更健康的区域。请注意,在节点出现故障后,在托管这些碎片的新节点从磁盘读取数据之前,碎片将部分不可用于读取。查询将返回部分数据(从最近到最近读取数据块) 结果是部分的。
当read客户端库从对区域A中Gorilla实例的查询中收到部分结果时,它将重试从区域B中获取受影响的时间序列,如果这些结果不是部分结果,则保留这些结果。如果区域A和区域B都返回部分结果,则这两个部分结果都被返回给调用者,并设置一个标志,表明某个错误导致了不完整的数据。然后,调用者可以决定是否有足够的信息来继续处理请求,或者是否应该彻底失败。我们做出这一选择是因为Gorilla最常被自动化系统用来检测时间序列中的数据变化。这些系统可以在只有部分数据的情况下运行良好,只要它是最新的数据。
从不正常的主机向正常的主机自动转发读取数据意味着用户可以避免重启和软件升级。我们发现,升级软件版本导致零数据丢失,并且所有读取继续成功提供,无需手动干预。这也允许Gorilla透明地提供从单个节点到整个区域的服务器故障读取服务[21]。最后,我们仍然使用我们的HBase TSDB来长期存储数据。如果所有内存中的数据副本都丢失了,我们的工程师仍然可以查询更耐用的存储系统来进行分析并驱动特别查询,而且Gorilla仍然可以实时检测重新启动并接受新的写入。
五、Gorilla上的新工具
Gorilla的低延迟查询处理支持新分析工具的创建。
5.1 关联引擎
第一个是在Gorilla中运行的时间序列关联引擎。相关性搜索允许用户对许多时间序列进行交互式的强力搜索,目前一次仅限于 100 万次。
关联引擎计算皮尔逊积矩相关系数(PPMCC),该系数将测试时间序列与大量时间序列进行比较[22]。我们发现PPMCC能够发现形状相似的时间序列之间的相关性,而不管规模如何,这极大地帮助了自动根本原因分析和回答问题 “在我的服务中断时发生了什么?”。我们发现这种方法对我们的问题给出了令人满意的答案,并且比文献[10,18,16]中描述的类似方法更易于实施。
为了计算 PPMCC,测试时间序列与所有时间序列密钥一起被分发到每个 Gorilla 主机。然后,每个主机独立计算前N个相关的时间序列,按PPMCC与指针比较的绝对值排序,并返回时间序列值。在未来,我们希望Gorilla能够在我们的监控时间序列数据上实现更高级的数据挖掘技术,例如文献中描述的用于聚类和异常检测的技术[10,11,16]。
5.2 绘图
低延迟查询也使得查询量更大的工具成为可能。例如,与监控团队无关的工程师已经创建了一个新的数据可视化,它将显示大量的水平图表,这些图表本身是许多时间序列的回归。这种可视化使用户能够快速直观地扫描大型数据集,以查看异常值和与时间相关的异常。
5.3 聚合
最近,我们将汇总后台进程从一组MapReduce作业转移到直接针对Gorilla运行。回想一下,ODS 对旧数据执行基于时间的聚合(或汇总)压缩,这是一种降低数据粒度的有损压缩 [26], 类似于Whisper使用的格式 [1]。在Gorilla之前,MapReduce作业是针对HBase集群运行的,该集群将读取过去一个小时的所有数据,并为一个新的、粒度更低的表输出值。现在,后台进程会定期扫描,每两个小时完成所有的存储桶,为较低粒度的表生成新值。因为在Gorilla中扫描所有数据非常高效,所以这一举动减少了HBase集群上的负载,因为我们不再需要将所有高粒度数据写入磁盘并在HBase上进行昂贵的全表扫描。
六、经验
6.1 容错
接下来,我们将描述过去6个月中发生的几起影响脸书部分站点可用性的计划内和计划外事件。我们仅限于讨论这些事件对Gorilla 的影响,因为其他问题超出了本文的范围。
网络中断。类似网络中断/机器某部分停机的意外事件。这些中断被自动检测到,Gorilla自动将读数转移到未受影响的海岸,没有任何服务中断。
配置更改和代码推送。有6个配置更改和6个代码发布需要在给定区域重新启动Gorilla。
BUG。一个有重大缺陷的版本被推到了一个海岸。Gorilla立即将负载转移到另一个区域,并继续提供服务,直到错误被修复。在提供的数据中存在最小的正确性问题。
单节点故障。有5个单机故障(与主要错误无关),没有造成数据丢失,也不需要补救。
在过去的6个月里,Gorilla中没有发生任何导致异常检测和警报问题的事件。自从Gorilla发布以来,只发生过一次中断实时监控的事件。在所有情况下,长期存储都能够作为所有监控相关查询的备份。
6.2 全站点错误率调试
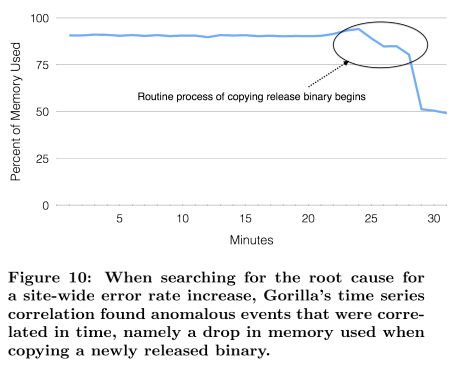
关于脸书如何使用时间序列数据来推动我们的监控,我们可以看看最近的一个问题,该问题由于监控数据而被快速检测并修复,首先在SREcon15 [19]中进行了外部描述。
一个神秘的问题导致了站点范围内的错误率激增。在错误率峰值出现几分钟后,Gorilla中的错误率是可见的,并在几分钟后发出警报,通知相应的团队[19]。然后,艰苦的工作开始了。当一组工程师缓解了问题时,其他人开始寻找根本原因。使用基于Gorilla构建的工具,包括第5节中描述的新的时间序列相关性搜索,他们能够发现将发布二进制文件复制到脸书的web服务器的常规过程导致了整个站点内存使用的异常下降,如图10所示。问题的检测、各种调试工作和根本原因分析都依赖于 Gorilla 高性能查询引擎提供的时间序列分析工具。
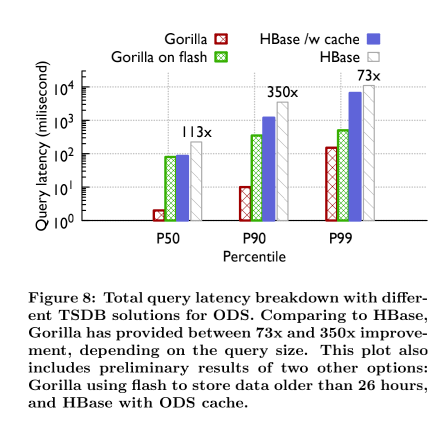
自大约18个月前推出以来,Gorilla已经帮助脸书的工程师确定并调试了几个这样的生产问题。通过将P90 Gorilla 查询时间减少到10ms,Gorilla还提高了开发人员的工作效率。此外,通过为Gorilla 85%的监控数据提供服务,很少的查询会命中HBase TSDB[26],从而降低了HBase集群的负载。
6.3 经验教训
优先考虑最近的数据而不是历史数据。Gorilla占据了一个有趣的优化和设计领域。虽然它必须非常可靠,但不需要ACID数据保证。事实上,我们发现最新的数据比任何以前的数据点更重要。这导致了有趣的设计权衡,例如在从磁盘读取旧数据之前,让Gorilla主机可供读取。
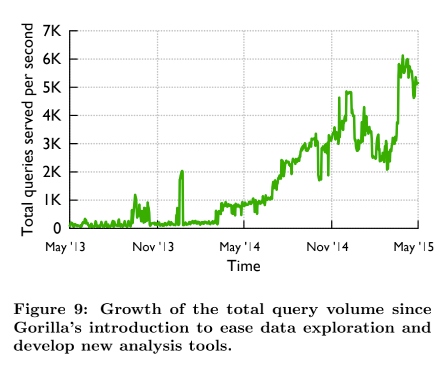
读取延迟很重要。压缩和内存中数据结构的高效使用实现了极快的读取速度并大幅提高了使用率。Gorilla推出时,ODS每秒处理450个查询,但Gorilla很快就超过了它,目前每秒处理超过5000个稳态查询,峰值曾一度达到到每秒40,000个峰值查询,如图9所示。低延迟读取鼓励我们的用户在Gorilla上构建高级数据分析工具,如第 5 节所述。
高可用性胜过资源效率。容错是Gorilla的一个重要设计目标。它需要能够承受单个主机故障,而不中断数据可用性。此外,该服务必须能够承受可能影响整个地区的灾难事件。因此,尽管效率受到影响,我们还是在内存中保留了两个冗余的数据副本。
我们发现构建一个可靠的容错系统是项目中最耗时的部分。虽然该团队在很短的时间内构建了一个高性能、压缩、内存中的TSDB原型,但又花了几个月的艰苦工作才使它具有容错能力。然而,当系统成功经受住真实的和模拟的故障时,容错的优势是显而易见的[21]。我们还受益于一个系统,我们可以在需要时安全地重启、 升级和添加新节点。这使我们能够以较低的运营开销有效地扩展Gorilla,同时为我们的客户提供高度可靠的服务。
七、未来的工作
我们希望以多种方式扩展Gorilla。一项努力是在基于内存Gorilla和HBase之间添加第二个更大的数据存储。这个中间层可以存放压缩的两个小时的数据块,但存储时间要长于 26 小时。我们发现,闪存允许我们存储大约两周的全分辨率、Gorilla压缩数据。这将延长全分辨率数据可供工程师调试问题的时间。初步性能结果如图 8所示。
在构建Gorilla之前,ODS依赖HBase后备存储作为实时数据存储:在数据被发送到ODS进行存储后不久,它就需要可供读取操作使用,这给HBase的磁盘 I/O 带来了巨大的负担。现在 Gorilla充当了最新数据的直写缓存,在数据被发送到ODS后,我们至少有26个小时的窗口,然后才能从HBase读取这些数据。我们通过重写写入路径,在写入HBase之前等待更长时间,来利用这一特性。这种优化在HBase上应该更有效,但这种努力太新,无法报告结果。
八、结论
Gorilla是我们在脸书开发和部署的一个新的内存时间序列数据库。Gorilla的功能相当于一个直写式缓存,用于在过去26小时内监控从脸书所有系统收集的数据。在本文中,我们描述了一种新的压缩方案,它允许我们高效地存储每分钟超过7亿个点的监控数据。此外,与之前的磁盘TSDB相比,Gorilla使我们的生产查询延迟降低了70 倍以上。Gorilla启用了新的监控工具,包括警报、自动补救和在线异常检查器。Gorilla在过去的18个月中一直处于部署状态,并取得了成功,在此期间,在没有太多运营工作的情况下,规模整整扩大了一倍,证明了我们解决方案的可扩展性。我们还通过以下方式验证了Gorilla的容错能力,几次大规模模拟故障和实际灾难情况,Gorilla在这些事件中保持了高读写可用性,有助于站点恢复。
引用
[1] Graphite - Scalable Realtime Graphing.http://graphite.wikidot.com/.Accessed March 20,2015.
[2] Inflfluxdb.com: InflfluxDB - Open Source Time Series,Metrics, and Analytics Database.http://inflfluxdb.com/. Accessed March 20, 2015.
[3] L. Abraham, J. Allen, O. Barykin, V. R. Borkar,B. Chopra, C. Gerea, D. Merl, J. Metzler, D. Reiss,S. Subramanian, J. L. Wiener, and O. Zed. Scuba:Diving into Data at Facebook. PVLDB,6(11):1057–1067, 2013.
[4] E. B. Boyer, M. C. Broomfifield, and T. A. Perrotti.GlusterFS One Storage Server to Rule Them All.Technical report, Los Alamos National Laboratory (LANL), 2012.
[5] N. Bronson, T. Lento, and J. L. Wiener. Open Data Challenges at Facebook. In Workshops Proceedings of the 31st International Conference on Data Engineering Workshops, ICDE Seoul, Korea. IEEE, 2015.
[6] T. D. Chandra, R. Griesemer, and J. Redstone. Paxos Made Live: An Engineering Perspective. In Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing,pages 398–407. ACM, 2007.
[7] H. Chen, J. Li, and P. Mohapatra. RACE: Time Series Compression with Rate Adaptivity and Error Bound for Sensor Networks. In Mobile Ad-hoc and Sensor Systems, 2004 IEEE International Conference on,pages 124–133. IEEE,2004.
[8] B. Hu, Y. Chen, and E. J. Keogh. Time Series Classifification under More Realistic Assumptions. In SDM, pages 578–586, 2013.
[9] E. Keogh, K. Chakrabarti, M. Pazzani, and S. Mehrotra. Locally Adaptive Dimensionality Reduction for Indexing Large Time Series Databases.ACM SIGMOD Record, 30(2):151–162, 2001.
[10] E. Keogh, S. Lonardi, and B.-c. Chiu. Finding Surprising Patterns in a Time Series Database in Linear Time and Space. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining,pages 550–556. ACM,2002.
[11] E. Keogh, S. Lonardi, and C. A. Ratanamahatana.Towards Parameter-Free Data Mining. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 206–215. ACM,2004.
[12] E. Keogh and C. A. Ratanamahatana. Exact Indexing of Dynamic Time Warping. Knowledge and information systems, 7(3):358–386, 2005.
[13] I. Lazaridis and S. Mehrotra. Capturing Sensor-Generated Time Series with Quality Guarantees. In Data Engineering, 2003. Proceedings.19th International Conference on, pages 429–440.IEEE, 2003.
[14] Leslie Lamport. Paxos Made Simple. SIGACT News,32(4):51–58,December 2001.
[15] J. Lin, E. Keogh, S. Lonardi, and B. Chiu. A Symbolic Representation of Time Series, with Implications for Streaming Algorithms. In Proceedings of the 8th ACM SIGMOD workshop on Research issues in data mining and knowledge discovery, pages 2–11. ACM, 2003.
[16] J. Lin, E. Keogh, S. Lonardi, J. P. Lankford, and D. M. Nystrom. Visually Mining and Monitoring Massive Time Series. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining,pages 460–469. ACM,2004.
[17] P. Lindstrom and M. Isenburg. Fast and Effiffifficient Compression of Floating-Point Data. Visualization and Computer Graphics, IEEE Transactions on,12(5):1245–1250, 2006.
[18] A. Mueen, S. Nath, and J. Liu. Fast Approximate Correlation for Massive Time-Series Data. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data, pages 171–182.ACM, 2010.
[19] R. Nishtala. Learning from Mistakes and Outages.Presented at SREcon,Santa Clara, CA, March 2015.
[20] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski,H. Lee, H. C. Li, R.McElroy, M. Paleczny, D. Peek,P. Saab, et al. Scaling Memcache at Facebook. In nsdi,volume 13, pages 385–398, 2013.
[21] J. Parikh. Keynote speech. Presented at @Scale Conference, San Francisco, CA, September 2014.
[22] K. Pearson. Note on regression and inheritance in the case of two parents. Proceedings of the Royal Society of London, 58(347-352):240–242,1895.
[23] F. Petitjean, G. Forestier, G. Webb, A. Nicholson,Y. Chen, and E. Keogh. Dynamic Time Warping Averaging of Time Series Allows Faster and More Accurate Classifification. In IEEE International Conference on Data Mining, 2014.
[24] T. Rakthanmanon, B. Campana, A. Mueen,G. Batista, B. Westover, Q. Zhu, J. Zakaria, and E. Keogh. Searching and Mining Trillions of Time Series Subsequences Under Dynamic Time Warping.In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining,pages 262–270. ACM, 2012.
[25] P. Ratanaworabhan, J. Ke, and M. Burtscher. Fast Lossless Compression of Scientifific Floating-Point Data. In DCC, pages 133–142. IEEE Computer Society, 2006.
[26] L. Tang, V. Venkataraman, and C. Thayer. Facebook’s Large Scale Monitoring System Built on HBase.Presented at Strata Conference, New York,2012.
[27] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka,S. Anthony, H. Liu, P. Wyckoffff, and R. Murthy. Hive:A Warehousing Solution Over a Map-Reduce Framework. PVLDB, 2(2):1626–1629, 2009.
[28] T. W. Wlodarczyk. Overview of Time Series Storage and Processing in a Cloud Environment. In Proceedings of the 2012 IEEE 4th International Conference on Cloud Computing Technology and Science (CloudCom), pages 625–628. IEEE Computer Society, 2012.