一、背景
Unikernel 是最小的单一用途虚拟机,目前在研究领域非常受欢迎,但是目前想把已有的应用程序移植到当前的unikernel环境是很困难的。HermiTux是第一个提供与Linux应用程序的系统调用级二进制兼容的unikernel,它由一个管理程序和一个模拟负载及运行时Linux ABI的轻量级内核层组成。HermiTux将应用程序开发人员从移植软件的负担中解脱出来,同时通过硬件辅助虚拟化隔离、快速启动时间和低磁盘/内存占⽤、安全性等提供单核优势。通过二进制分析重写技术及共享库替换,可以快速实现系统调用和内核模块化。
论文中展示了HermiTux的独立架构特色,在x86-64和ARM aarch64 ISA架构上展示了一个原型,针对各种云以及边缘/嵌入式部署,也展示了HermiTux对⼀系列原⽣C/C++/Fortran/Python Linux 应⽤程序的兼容性。HermiTux与其他unikernel相比,也提供了相似程度的轻量级,并且在许多情况下与Linux性能相似,它在内存和计算密集型场景下性能开销平均损失3%,其I/O性能是可以接受的。
二、HermiTux对于Linux程序兼容性的思路
Unikernels在学术领域变得很流行,它以虚拟化LibOS模型为基础,这种模型也带来了很多好处,主要包括:提高安全性、性能改进、隔离性提升、降低成本等。这样的优势也增加了很多应用场景:云和边缘部署的微服务/基于Saas和Faas的软件、服务器应用程序、NFV、IOT、HPC等。尽管unikernel被视为容器领域具有吸引力的替代品,但unikernels仍然在行业中很难获得显著的牵引力,并且它们的采用率相当缓慢,主要原因是将遗留/现有的应用程序移植到unikernel模型很困难,有时候甚至是不可能的。
在大型程序中,移植复杂的代码库很困难,这是由于诸如不兼容/缺少库/函数、复杂的构建过程、缺乏开发工具(调试器/分析器)、不受支持的语言等因素存在。移植到unikernel环境,也需要程序员具备这方面的专业知识,巨大的移植负担是阻碍广泛采用unikernels最大的障碍之一。
HermiTux提出了一个新型的unikernel模型,他为常规Linux应用程序提供二进制兼容性,同时保留了unikernel的优势,它允许开发工作集中在unikernel这层。HermiTux原型是HermitCore unikernel的扩展,它能够运行原生的Linux可执行文件作为unikernel。通过提供这种基础设施,HermiTux将应用程序员的移植工作转变为unikernel层开发人员的支持工作,在这个模型下不仅可以让原生Linux应用程序透明地获得unikernel的好处,而且还可以运行以前不可移植的应用程序。使用HermiTux将遗留应用程序作为unikernel移植和运行是不存在的,HermiTux支持静态和动态链接的可执行文件、兼容多种语言(C/C++/Fortran/Python等)、编译器(GCC和LLVM)、全面优化(-O3)和剥离/混淆的二进制文件。它支持多线程和对称多处理器(SMP)、检查点/重启和迁移。
大多数现有的unikernel不提供任何类型的二进制兼容性,一些系统通过在C库级别进行接口适配来提供二进制兼容性,其作用类似于动态链接库。这可以防止它们通过系统调用来支持何种需要操作系统服务的应用程序,而无需通过C库。为了保障最大化的兼容性,HermiTux没有采用通用做法,在系统调用级别实现了所有应用程序和编译库使用的标准化接口。
三、HermiTux的挑战
HermiTux应对的第一个挑战是如何提供系统调用级别的二进制兼容性?,因此HermiTux根据Linux应用程序二进制接口ABI设置执行环境并在运行时模拟OS接口。基于自定义管理程序的ELF加载程序用于在单个空间虚拟机中与最小内核一起运行Linux二进制文件。程序运行的系统调用被重定向到unikernel提供的实现。
HermiTux应对的第二个挑战是如何在**提供二进制兼容性的同时保持unikernel的好处?**有些是自然具备的好处(小磁盘/内存占用、虚拟化强制隔离),而另一些(快速的系统调用、内核模块化)在假设无法访问源代码时会带来技术挑战。为了实现这些好处,HermiTux对于静态可执行文件使用了二进制重写与分析技术,并在运行时用一个可识别的unikernel的C库替代动态链接库的可执行文件。最后HermiTux针对低磁盘/内存占用和攻击面进行了优化,与现有的unikernel一样低或更低。
由于unikernel应用案例广泛,HermiTux当前目的是兼容服务器和嵌入式虚拟化场景,因此主要支持Intel x86-64和 ARM aarch64 (ARM64) 指令集架构 (ISA) 开发。HermiTux的设计基本原则是独立于架构,但是它的实现以及我们用来恢复unikernel的二进制重写/分析技术是ISA特定的。
总体来说,HermiTux做了以下出色工作:
- 一种新的unikernel模型,旨在执行本机Linux可执行程序,同时保持经典的unikernel优势。
- 提供可以在x86-64 和 aarch64 架构上的两个原型实现。
四、关键概念阐述
4.1 Unikernels
unikernel是一个应用程序,它使用必要的库和一个精简OS层静态编译成一个二进制文件,能够作为虚拟机在管理程序上执行。Unikernel符合以下条件:
- 单一目的:一个unikernel只包含一个应用程序
- 单一地址空间:由于单一目的原则,所以unikernel不需要内存保护,因此应用程序和内核共享一个地址空间,所有代码都以最高权限级别执行。
这样的模型提供了显著的好处,在安全性方面提供了unikernel之间的强隔离,虚拟机管理程序让它成为云部署的良好候选者。此外unikernel仅包含运行给定应用程序所需的必要软件。结合非常小的内核尺寸,和常规VM相比,这导致应用程序攻击面显著减少。一些unikernel也是用提供内存安全保障的语言编写的。关于性能方面,unikernel系统调用很快,因为它们是常见的函数调用,特权级别之间没有代价昂贵的用户态与内核态切换。上下文切换也很快,因为没有页表切换或TLB刷新。除了由于小内核导致代码库减少之外,unikernel OS层通常是模块化的,可以将它们配置为仅包含给定应用程序的必要功能。
所有这些好处让unikernels的应用程序域非常丰富。他们非常适合运行大多数需要高度隔离的云应用程序和需要高性能、低操作系统开销的计算密集型作业的数据中心。unikernel减少的资源使用使它们特别适合嵌入式虚拟化,随着边缘计算和物联网等范式的出现,这个领域的重要性日益增加。由于unikernels的应用领域包括服务器和嵌入式机器,因此论文主要针对intel x86-64和 aarch64架构进行模型构建。
4.2将现有应用程序移植到Unikernel
移植现有软件作为unikernel运行是很困难的,特别在某些情况下无法移植程序到unikernel环境,因为所有的程序都需要重新编译与链接。一个给定的unikernel支持一组有限的内核特性和软件库,如果不支持应用程序所需的函数、库或者特定版本的库,则该程序需要进行调整。在许多情况下,缺少函数/库意味着应用程序根本无法移植,此外unikernel使用复杂的构建基础架构,将一些遗留的应用程序(大型的Makefile、autotools、cmake)移植到unikernel工具链会很麻烦,更改编译器或者构建选项也是如此。
在如此大的移植成本上,所以unikernel发展缓慢是有原因的,一种解决方案是让unikernel为常规可执行文件提供二进制兼容性,同时仍保持经典 unikernel 的优势,例如⼩代码库/占⽤空间、快速启动时间、模块化等。这种新模型允许 unikernel 开发⼈员致⼒于推⼴unikernel 层以⽀持最⼤应⽤程序的数量,并减轻应⽤程序开 发⼈员的任何移植⼯作。这种⽅法还应该⽀持调试器等开发⼯具。在这种情况下,HermiTux 允许将 Linux ⼆进制⽂件作为unikernel 运⾏,同时保持上述优势。
4.3 轻量级虚拟化设计空间
轻量级虚拟化设计空间包含unikernel、面向安全的LibOS、例如Graphene,以及带有软件和硬件强化技术的容器。HermiTux不需要应用程序移植工作,并且和其他二进制兼容的系统方案不同,不同点主要包括:
- 作为unikernel HermiTux运行硬件强制(扩展页表)虚拟机,这是一种从根本上比软件强制隔离(容器/软件LibOS)更强的隔离机制。当前在VM中运行容器以确保安全的趋势(clear containers)加强容器隔离的努力(gVisor)都表明了这一点,这通常用作支持unikernel与容器的安全依据。
- HermiTux使更广泛的应用程序能够透明地无需任何移植工作即可获得unikernel的好处,无需修改代码以及维护单独分支的潜在复杂性。鉴于unikernel提供的安全性和减少占用空间的特性,这在当今的计算机系统环境中非常有价值,软件和硬件漏洞经常成为新闻,并且数据中心架构师正在寻求增加整合和减少资源/能源消耗的方法。二进制兼容允许HermiTux成为专有软件(其源代码不可用)作为unikernel运行的唯一方法。最后,HermiTux允许软件获得VM的传统优势,例如检查点/重启/迁移,而无需大量磁盘/内存占用的相关开销。
4.4 系统调用级二进制兼容
两个现有的unikernel已经生成和应用程序的二进制兼容,OSv和Lupin Linux。需要注意的是,两者都提供二进制兼容性标准C库(libc)级别,unikernel包含一个动态加载程序,它在运行时捕获对libc函数的调用,例如printf、fopen并将它重定向到内核。
这种接口方法意味着假设所有系统调用都是通过libc进行的,当考虑到各种各样的现代应用程序二进制文件时,这并不成立。我们分析了整个Debian10 x86-64存储库 (主要,贡献 和 ⾮免费) 并统计了553个ELF可执⾏⽂件,包括⾄少⼀次调⽤系统调⽤指令:这些代表不通过libc 执⾏系统调⽤程序,因此 libc 级别的⼆进制兼容unikernel 不⽀持这些程序。这种有限的libc级兼容性组织了这些系统运行相对较大范围的应用程序,这些应用程序将从座位unikernel的执行中受益匪浅。举几个例子,大量的云服务是用Go语言编写的,Go是一种无须标准C库即可执行大多数系统调用的语言。此外,由于在系统调用层面缺乏兼容性,OSv不支持最流行的HPC共享内存编程框架OpenMP,最后libc接口排除了对静态二进制文件的支持。
HermiTux代表了一种尝试,通过增加一个更加标准和一致使用的接口(系统调用级别)上进行接口来进一步推动unikernel的兼容性程度。
五、系统设计
HermiTux的设计基于以下假设:假设二进制文件的源码不可用;不对使用的编译器、优化级别或二进制文件是否被剥离或混淆做假设。因此拆卸和重新组装,通常被认为是非常不靠谱的,不是一个合适的解决方案,所以HermiTux决定提供与Linux操作系统的二进制兼容性。
Linux ABI,为了提供二进制兼容性,HermiTux的内核需要遵守构建Linux ABI的规则集。这些规则部分是特定与ISA的,可以大致分为加载时规则和运行时规则。加载时规则包括支持的二进制格式(ELF)、应用程序可以访问64位地址空间以及特定的寄存器状态(ISA-specific)和堆栈布局(命令行参数、环境变量、ELF辅助向量)预期在应用程序入口点。运行时负责包括用于触发系统调用的指令,以及包含其参数和返回值的寄存器,这些显然是特定于ISA的。最后函数、系统以及通过与内核共享的内存区域:vDSO/vsyscall。
5.1 系统概述
HermiTux的设计目标是在加载和运行时模拟Linux ABI,同时提供unikernel原则,通过使用自定义ELF加载程序来确保加载时间要求。运行时约定是HermiTux的内核中实现类似Linux的系统调用处理程序。vDSO/vsyscall和虚拟文件系统访问通过进一步描述的方法进行模拟。
最后HermiTux保持了一些unikernel的好处,即快速的系统调用和模块化,而不假设使用静态可执行文件的二进制重写和分析技术访问应用程序源。对于动态编译的程序,我们使用在运行时加载可识别的unikernel的共享标准C库来替代程序链接的原始标准库。HermiTux的内核作为HermitCore unikernel的扩展而开发的。

图一展示了系统的高级视图,来自一个名叫Uhyve的自定义轻量级管理程序,它在Linux主体中运行并利用KVM接口创建虚拟机。Uhyve最初是为HermitCore开发的,并在Hermi-Tux的上下文进行了扩展。在启动时,Uhyve为来宾分配内存作为其物理内存。接下来,管理程序在该区域的特定位置加载HermiTux内核(如图1中的A),然后继续在ELF元数据中制定的位置映射来自Linux二进制文件的可加载ELF段。在加载过程之后,控制权被传递给来宾并且内核初始化。设置页表是为了构建包含内核和应用程序的单个地址空间。
遵循unikernel原则,初始化之后,内核按照Linux加载约定为应用程序分配和初始化一个堆栈,然后跳转到可执行入口点B,其地址是在加载时从ELF元数据中读取。在应用程序执行期间,系统调用将根据Linux约定执行,即使用系统调用x86-64指令或SVC(主管调用)aarch64的指令。内核通过实现一个系统调用处理程序来捕获此类调用,该处理器识别所调用的系统调用,确定来自CPU寄存器的参数,并调用所考虑的系统调用C的HermiTux实现。
5.2 加载时二进制兼容性
在加载时,管理程序将内核和Linux应用程序可加载ELF段复制到来宾内存中ELF元数据中指示的虚拟地址处。应用程序和内核都在单个地址空间中运行,因此我们需要确保为两个实体静态和动态分配的代码/数据不会重叠。这是通过将内核定位在专用与应用程序的内存区域之外来完成的。和Linux不同,Linux致力于上半部分内核的48位虚拟地址空间,由于HermiTux内核的虚拟/物理内存需求⾮常⼩,我们可以将其定位在0x200000,以下为应⽤程序保留的区域。这使应用程序可以访问虚拟地址空间的主要部分,并具有为随机映射启动非常高的熵的有趣副作用:34位高于vanilla Linux(28 位),以及PaX/grsecurity 强化内核(33 位)。
HermiTux支持动态编译的二进制文件如下:当加载器检测到这样的二进制文件时,它加载并将控制传给动态加载器,该加载器依次加载应用程序及库依赖项,并负责符号的重定位。由于其二进制兼容性,在HermiTux中,动态加载器是常规Linux加载器的未修改版本。与Kylinx不同的是,HermiTux不在虚拟地址空间中共享多个unikernel之间的动态库,这主要是出于安全原因,因为VM之间的共享内存使它们容易受到侧通道攻击,例如Flush+Reload或Prime+Probe。而且,如果安全性不那么重要并且内存受到使用限制,那么内存同页合并(KSM)是解决该问题的一种标准且有效的方法。虽然动态二进制文件受到Linux发行版维护者的青睐,但静态可执行文件在性能和兼容性方面仍然具有优势。HermiTux的目标是兼容这两种链接类型。
5.3 运行时二进制兼容性
在unikernel中,系统调用是常见的函数调用。在HermiTux中,应用程序使用(特定于ISA)的Linux约定执行系统调用,现有的unikernel不支持。HermiTux实现了一个系统调用处理程序,当应用程序执行触发系统调用的特定指令时调用该程序处理程序。处理程序将执行重定向到所调用的内部unikernel实现(图1中的C)。在系统调用级别与应用程序接口是HermiTux提供的运行时二进制兼容性的核心。这意味着我们的原型在C/C++/Fortran/Python编写的软件上进行测试,可以很容易地扩展到其他语言和运行时。
Vanilla HermitCore只支持极少数的系统调用,我们不得不在HermiTux中扩展这个接口。在unikernel上下文中,为未修改的Linux应用程序开发系统调用支持可能会引起代码库大小和复杂性增加方面的担忧。直观地说,最终重新实现Linux也可能是一项非常庞大的工程工作。然而对于我们的工作来说,这并不代表Linux系统调用接口的完全重新实现,虽然它相对较大(超过350个系统调用),但应用程序通常只使用该接口的一小部分。它还表明,通过实现少至200个系统调用就可以支持标准发行版的90%的应用程序,HermiTux原型中实现了107个系统调用。源兼容unikernel,例如OSv或Rumprun。还表明支持较大部分的Linux系统调用API不会导致代码库大小或攻击面的显著增加。
5.4 unikernel的好处和隔离
unikernel中系统调用延迟很低,因为它们是常见的函数调用。尽管系统调用处理程序针对unikernel上下文进行了优化,但我们观察到在HermiTux中,这种延迟仍然没有接近函数调用,这是由于用于执行未修改Linux二进制文件中使用的系统调用的指令。在x86-64和aarch64 ISA中,该指令依赖于异常,这种操作的延迟明显高于普通调用指令的延迟。
在不假设可以访问应用程序源代码的情况下,我们依靠两种技术在HermiTux中提供快速系统调用(fastcall在图1)。对于静态二进制文件,我们使用二进制检测重写应用程序的系统调用命令,并使用对相应unikernel实现的常规函数调用。这个过程是ISA特定的。对于动态链接程序,我们观察到在大多数应用程序的二进制文件中,大多数系统调用由标准C库进行。考虑到这一点,在HermiTux中,动态二进制文件再加载时链接到我们设计的支持unikernel的C标准库,其中所有系统调用都被内核的函数调用切换,我们称这种技术为库替换。它与OSv内核和LibC应用程序接口的方式相似。在论文中,HermiTux团队也不是从头开始编写Libc,而是使用代码转换工具Coccinelle自动适应现有的Libc,与从头开始编写Libc相比,我们相信该解决方案不仅为Libc功能提供了更大的支持,而且更加健壮和面向未来。
模块化的unikernel的另外一个重要好处,由于我们的二进制兼容目标,系统调用库代码在HermiTux中比较大。我们设计内核,以便每个系统调用的时间可以在内核构建时编译入和编译出。除了减少内存占用之外,这还具有比传统系统调用过滤(例如seccomp)更强的安全优势,不仅无法调用相关的系统调用,而且它们的实现完全不在内核中,这意味着它们不能用于代码重用攻击。为了可以给不一定可用的给定应用程序编译定制的内核,我们设计了一个二进制分析工具,能够扫描可执行文件并检测该程序可以进行的各种系统调用。
HermitCore将文件系统调用转发到主机引起了对于安全/隔离的明显担忧。我们实现了一个基本的RAM文件系统,在HermiTux内核中,禁用对主机的任何依赖。MiniFS还模拟了具有可配置的perfile读写功能的伪文件:我们 /dev/zero和一个自定义读取函数,用零填充用户缓冲区,/dev/cpuinfo使用读取函数填充缓冲区,其中包含有关CPU等类似Linux的文本信息。
六、HermiTux的实现
HermiTux建立在HermitCore之上,在HermitCore的20k LoC之上增加了15k LoC。它同时支持x86-64和aarch64。尽管我们系统的设计原则是独立于架构的,但其实现的小子集是特定于架构的。
加载和初始化,管理程序根据二进制文件中的ELF元数据设置VM并将内核和应用程序加载到内存中。如果应用程序支持PIC/PIE,它会在随机位置加载。接下来,内核初始化并创建一个定义单个地址空间的页表。初始化后,内核为应用程序创建一个任务。应用程序将与内核共享它的堆栈,因此堆栈根据ABI约定填充元素(命令行参数等),并在x86-64上进行了一系列Push操作。在aarach64上做同样的事情是不切实际的,因为这个ISA只支持16字节对齐的Push操作,而且我们希望Push的许多元素大小都是8字节。因此,我们填充了一个临时缓冲区,该缓冲区最终被复制到堆栈中,并可能有一个字节的填充。
系统调用处理,内核安装并实现了一个遵循Linux ABI的系统调用处理程序,系统调用地址在%rax/%x8;参数在%rdi, %rsi, %rdx,%r10, %r9, %r8/%x0-%x5;返回值对于x86-64/aarch64在%rax/%r0。处理程序保存寄存器的内容,调用所实现的系统调用实现,并在返回之前恢复寄存器。经过优化,在单核中不需要许多的“world switch”操作(例如堆栈切换)。返回时,我们还可以避免昂贵的指令,例如系统在x86-64上并用简单的跳转替换系统调用。
HermiTux目前支持107个系统调用,许多只是部分支持,例如ioctl仅支持LibC初始化所需的命令。4k LoC专用与系统调用层,这表明HermiTux可以保留一个小的unikernel代码库。通过支持的系统调用,HermiTux能够模拟Linux对网络、文件系统、多线程和同步、内存映射、进程管理、信号、时间管理和调度的支持。
快速系统调用,在基本形式中,HermiTux使用传统的系统调用处理程序,因此失去了低延迟系统调用的单内核优势。为了动态编译的二进制文件恢复该功能,我们在运行时链接到一个支持unikernel的标准C库。在运行时加载动态二进制文件的unikernel感知C库改编自Musl Libc。我们使用Coccinelle工具来描述高级代码转换规则,将系统调用更新为对HermiTux内核的函数调用。通过一小组规则(80行),我们能够更新整个库中500多个系统调用的97.5% 。我们证明这种方法在时隔多年发布的不同版本的Musl上是成功的。
关于静态二进制文件,我们采用二进制重写,静态实现避免任何运行时开销。我们的目标是替换系统调用指令的出现(系统调用对于x86-64、SVC对于aarch64)。对于x86-64,一种指令大小可变的ISA,主要挑战在于系统调用:2个字节。它太小了,不能用任何类型的替代调用或类似跳转的指令,而不覆盖代码段中的下一条指令。为了解决这个问题,我们覆盖了每次出现系统调用指令以及下一条指令跳转到为我们开发的一段代码。这段代码负责首先将Linux syscall ABI适配到函数调用system-V约定(例如移动 %r10 到 %rcx)。内核中的系统调用实现是用普通的函数调用指令调用的,调用最后系统调用最初被覆盖的指令被重放,然后调回最后一个被覆盖指令之后的指令。虽然这个过程除了函数调用之外还包括一些操作,但它比传统的系统调用要快得多。
另一方面,aarch64是一个固定大小的指令集,因此不会遇到与x86-64相同的问题。至关的系统调用指令SVC可以简单地用函数调用覆盖,即BL(分支与链接)对一下说明没有副作用。aarch64的实际挑战在于一个重要的ABI点:与x86-64将返回地址存储在堆栈中相反,aarch64将其保留在特殊的寄存器%x30。因此,当我们替换系统调用指令时SVC使用函数调用BL,BL覆盖%x30用新插入的函数(即系统调用实现)应该返回的地址保存当前函数的返回地址。
在这种情况下,人们可能会认为我们会是去从调用系统函数返回的可能性,这当然会破坏程序。但是,我们意识到在许多情况下,无需借助复杂的解决方案(例如我们在x86-64的解决方案)即可解决此问题。首先,在常见情况下,系统调用调用的函数同时调用其他函数,这要求%x30由编译器生成的代码保存在堆栈中,并从相关函数返回时恢复,因此即使覆盖SVC通过BL(分支与连接)丢弃%r30的值,它将在返回之前正确恢复。二、少数系统调用如exit永不返回因此损失%x30是可以接受的。结合起来,这三种情况涵盖了标准libc(Musl)中超过90%的系统调用。我们使用angr二进制分析工具来识别它们并通过函数调用执行系统调用的安全替换。剩下的10%系统调用通过标准的基于陷阱的处理机制。
基于系统调用的模块化,随着对Linux ABI的支持越来越多,HermiTux涉及系统调用实现的代码库子集相对较大,它目前约占整个unikernel代码库的 25%。为了将unikernel的”模块化“特性带回HermiTux,我们建议编译定制的内核,只包含应用程序所需的系统调用的实现。这是通过在其子集的编译单元(C源文件)中实现尽可能多的每个系统调用的处理代码,并使用预处理指令来启用/禁用对系统调用实现的调用来实现的(sys_*)在构建时根据需要从通用系统调用处理程序中获取。
为了利用此功能并给应用程序构建一个定制的内核,有必要了解可能由所述应用程序调用的整个系统调用集。为此,我们决定依靠静态分析,由于我们不假设可以访问应用程序源代码,因此我们求助于反编译二进制文件。借助系统调用ABI约定的知识,我们在反编译的机器代码中寻找系统调用处,并在这些点确定保存系统调用标识符的寄存器中存储的值:%rax对于x86-64,%r8对于aarch64。这种技术适用于静态和动态编译的二进制文件,对于后者,它可以应用于应用程序二进制文件以及库。我们对x86-64使用Dyninst和对aarch64使用Angr来反编译二进制文件并获得CFG。我们向后迭代指令流,直到找到以%rax/%r8加载值的系统调用。这个搜索很简单,对于Glibc,我们找到了一个调用点,其中该值来自内存,因此无法静态识别。查看相应的C代码可以容易确定它实际上是read系统调用。为了解决这种情况,我们创建了一个查找表,该表返回由此类静态无法识别的系统调用的库函数进行的系统调用。
除了基于系统调用的模块化之外,我们还启动了最初(在HermitCore中)包含在所有构建中的模块化粗粒度组件,例如LWIP、TCP/IP堆栈。
七、评估
评估的目的是回答以下问题:
- HermiTux是否在运行原生Linux二进制文件的同时保持unikernel的轻量级优势,即低磁盘/内存占用和快速启动速度?
- 在这些指标方面,它与其他轻量级虚拟机解决方案相比如何?
- 当我们专注于原生/遗留可执行文件时,HermiTux可以执行用不同语言编写、剥离、混淆、完全优化和不同编译器/库编译的二进制文件吗?
- HermiTux的性能与其他轻量级虚拟化解决方案相比如何?
我们在多个宏观和微观基准上评估了HermiTux。HermiTux与几个轻量级虚拟化解决方案进行了对比,包括Linux VM、Firecracker、Docker,三个专注于与现有应用程序兼容的unikernels模型上:Lupine Linux、Osv和Rumprun。对于他们每个系统,均使用各自git仓库中可用的最新版本。与HermiTux不同的是,这些unikernel都不是在系统调用级别与Linux二进制兼容与Linux二进制安全(Lupine的 ”pure“ unikernel形式由kernel mode linux启用在libc接口层强制进行的KML)。出于兼容性原因,Lupin和OSv在Firecracker之上运行,而Rump在Solo5上运行。Lupin不支持aarch64,在网络绑定设置中,出于性能原因,我们还在Qemu之上运行所有的VM。我们使用的宏基准包括C/Fortran/C++/Python NPM、PARSEC和Python Performance Benchmark Suite。我们还基于PARSEC的StreamCluster计算内核构建了一个边缘计算基准。微基准包括redis-benchmark和LMbench测量系统调用延迟。
我们希望评估HermiTux在数据中心/云和边缘环境中的效率,并且我们在x86-64和aarch64架构上运行试验。x86-64机器是Intel Xeon E5-2637(3.0 GHz,64 GB RAM),以Linux v4.4.0作为主机运行Ubuntu Server 16.04。它是数据中心中典型服务器。aarch64机器是LibreComputer LePotato单板计算器,具有主频为1.5Ghz的aarch64 CPU和2GBde RAM。它以Linux v4.19.0作为主机运行Ubuntu 18.04。它代表了在云边缘的某一类低功耗嵌入式系统。除非另有说明,否则使用的编译器是GCC/G++ v6.3.0(x86-64)和v8.3.0(aarch64),并且使用-O3级别优化。
除了这里介绍的实验之外,我们还通过确认HermiTux对其他语言(如Rust、Lua和Nim)的基本支持来验证我们的系统调用级别的二进制兼容性。
7.1 轻量化:减少占用空间和启动时间
启动时间,在需要反应性或弹性的情况下,该指标对于unikernel至关重要。在相关工作中以各种方式测量了引导和销毁的延迟。尽管虚拟机管理程序初始化时间有时不可忽略,但应用可以在各种虚拟机监视器上运行,我们选择将虚拟机管理程序初始化时间排除在研究之外,只考虑应用启动时间,因此,我们将启动时间定义为启动unikernel时虚拟机管理程序开始执行应用代码的时刻与应用内核初始化后运行用户代码的第一条指令之间的延迟。为此,我们检测了虚拟机管理程序(Uhyve、Firecracker和Solo5)和guest kernel。管理程序被修改为在guest执行开始之前获取时间戳。通过在内核启动过程之后立即插入到管理程序的陷阱来检测guest内核,该陷阱又需要时间戳,对于Docker,我们使用docker events来比较container start和container die之间的差异。

启动速度上,如图2所示,HermiTux继承了及基础HermitCore的快速和优化启动时间:x86-64为33ms,aarch64上为5ms。在x86-64上,它比OSv(13毫秒)和Rump(17毫秒)稍慢,但在aarch64上要快得多(OSv为34毫秒,Rump为50毫秒)。HermiTux的启动速度也比Docker快得多:x86-64为3倍,aarch64为26倍。关于Lupin,正如相关论文中提到的,它的启动时间收到KML补丁的影响:使用KML Lupin的应用程序可以享受快速的系统调用,但是启动时间是HermiTux的3倍:94毫秒。如果没有KML,它会下降到41毫秒。不出所料,传统内核(Alipine)的数值要高很多,比HermiTux高20倍(x86-64)和237倍(aarch64)。
内存使用情况,低内存占用是unikernel模型的承诺之一,与启动时间类似,相同工作已使用各种方法来测量RAM使用情况。我们再次选择排除管理程序的内部内存占用,因此我们将RAM使用定义为可以提供给虚拟机执行”hello world“程序的最小内存量。我们将此方法用于unikernels和Alpine VM,针对Docker使用docker enents进行统计。
如图二所示,继承自HermitCore的HermiTux的简约设计允许提供低内存占用:x86-64和arrach64为11MB。Rump在x86(8MB)上的内存使用量略小,但在aarch64(24MB)上高出两倍多。在两种ISA上,OSv的RAM占用量也高于HermiTux:在x86-64上超过2倍,在aarch64上超过1.3倍。在x86-64上,Lupin的占用空间是HermiTux的1.8倍。不出所料,Alipine VM在两个ISA上的内存使用率都较高,为34MB,而docker容器的内存使用率最低,为6MB。
镜像大小,最后,我们比较了每个解决方案的简单”hello world“应用程序的硬盘镜像大小。对于已编译的unikernel,它只是unikernel二进制文件的大小。对于HermiTux,他是内核和应用程序二进制文件的总和。我们还报告了应用程序二进制文件本身(即空容器的占用空间),以及Alipine容器和VM的磁盘镜像大小。
结果如图二所示,改变支持它的系统ISA只会导致较小的磁盘占用。正如人们所看到的,HermiTux提供了非常小的镜像大小:x86-64上位1.2MB,aarch64上为530KB。这个好处再次来自HermitCore的极简设计。它与其他所有小于5MB的unikernel镜像大小相似或更好,而ARM上的OSv为7MB。Alpine VM的占用空间最高:35MB,而对于Alpine容器,占用空间相对较低:5MB。请注意,应用程序的二进制大小可以忽略不计(大约10KB),这表明其中大部分是由内核等系统软件占用的。
我们可以得到结论,在HermiTux中保留了unikernel的轻量级优势,因为它与最先进的unikernel相当,有时甚至更好。系统调用模块化,我们使用系统调用分析工具分析了一组针对Musl libc编译的应用程序,并为x86-64和aarch64编译了一组HermiTux内核,每个内核都针对应用程序仅支持应用程序进行的系统调用。

表1显示了进行的系统调用的数量以及与具备完整系统调用支持的内核相比,定制内核带来的内核代码段大小减少方面的节省。我们选择代码段大小作为度量标准,因为减小其大小可以提高安全性。实际上,该段映射有可执行权限,是代码重用攻击的潜在目标。在表1中,最小的标识具有最小系统调用使用的应用程序的内核,它的主要是函数直接返回。结果表明,编译定制的内核可以显着减少内核代码大小。例如,对于Blackscholes,aarch64的代码减少量为24%,x86-64的代码量减少了17%。更多系统调用密集型的应用程序的大小减少幅度更小:aarch64减少了16%,使用SQLite的x86-64减少了11%。随着对更多系统调用的支持被添加到HermiTux,我们预计这些数字会增长。
这些实验表明HermiTux提供低镜像大小、RAM使用、启动时间和模块化内核代码库,同时Linux应用程序二进制兼容。
7.2 应用支持:编译场景
为了演示HermiTux的通用性,我们在不同配置下从NPB套件编译了一个程序,我们改变了编译器(针对x86-64的GCC v6.3.0和针对aarch64的v8.3.0,以及针对两种ISA的LLVM v4.0.1)、C库(Musl和Glibc)以及基准语言写于:NPB有C和Fortran实现。两个附加配置包括剥离和混淆二进制。混淆通常用于涉及专有软件的场景,它是使用Obfuscator-LLVM实现的,这是一种在LLVM中间表示上应用混淆传递的开源工具。我们完全激活了这些混淆技术:指令替换、虚假控制流输入和控制流扁平化。-O3为所有的配置启用了优化级别,实验在x86-64服务器和aarch64嵌入式主板上运行。我们为x86-64选择NPB BT A类,为aarch64选择CG A类,因为它们在每台机器上运行足够长的时间(数10秒)。

Linux和HermiTux的执行时间非常相似,如图3所示,对于所有实验和两种架构,Linux和HermiTux之间的差异保持在2%一下。
对于x86-64,我们还可以观察到使用LLVM编译带来了大约15%的的性能提升。值得注意的是,我们使用的LLVM版本(v4.0.1)比x86-64的GCC版本(v6.3.0)略新。对于aarch64,GCC比LLVM快约12%。在这种情况下,我们用于该ISA的GCC版本(v8.3.0)比LLVM的版本(v4.0.1)更新得多。
我们选择的混淆选择组合导致x86-64上的速度下降146%,而aarch64上的速度下降449%。两种ISA中的Linux和HermiTux的性能下降是相似的。由于混淆开销,它们是可以预料的。改变C库和语言不会影响这种计算/内存密集型的工作负载的性能。
7.3 一般性能
x86-64上的内存和计算约束基准,我们在x86-64服务器上运行了一组来自NPB(BT/IS/EP)、PARSEC(Swaptions和Stream Cluster)和Python性能基准(Nbody)的基准。请注意,HermiTux能够运行基准套件中的其他程序,论文里没有给出结果。为了支持Python,HermiTux运行Micropython轻量级解释器。
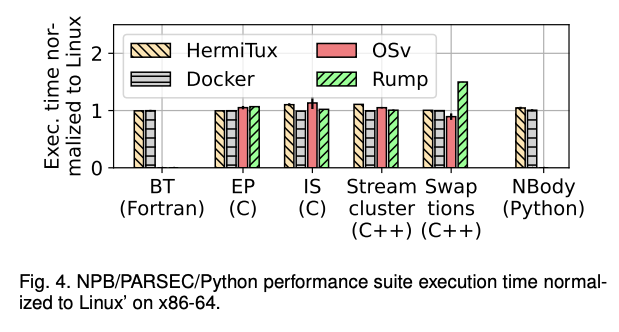
结果如图4所示,其中执行时间标准化为Linux的执行时间:y轴的1代表Linux的执行时间。OSv和Rump不支持Fortran或Micropython。这些基准尚未移植到Lupin上运行,但我们预计运行时类似于Linux,因为系统调用延迟不是瓶颈。
HermiTux的性能与Linux类似:HermiTux和Linux运行时在所有基准测试中的平均差异为2.7%(包括NPM/PARSEC/Python基准测试)。对于一些基准测试(eg:IS),观察到HermiTux开销略高。原因是这些测试的运行时间非常短:几秒钟。在这些情况下,基准测试非常短,以至于打印到标准输出的I/O成为延迟的重要来源(对于我们使用的HermiTux测试,此类I/O被转发到主机)。
与Linux相比,Docker和OSv的结果也非常相似。Rump也是如此,但是可以观察到Swaptions的显著放缓(50%)。Rump缺乏分析工具,我们无法查明这种退化的确切原因。一种解释可能是Rump工具链稍旧:它使用g++ v5.4.0,而所有其他系统都使用 g++ v6.3.0。
x86-64上的网络性能,为了评估HermiTux的网络性能,我们使用了Redis。Redis是一种广泛使用的键值存储服务器,特别是因为它作为服务器应用程序的安全要求,它是unikernel部署的完美目标。在我们的x86-64服务器上,我们在前面提到的虚拟化解决方案中运行Redis。由于Firecracker的网络支持尚未与Qemu相提并论。我们从具有20个并行客户端和2字节密钥大小的主机进行redis-benchmark,以在对延迟极其敏感的情况下对系统施加压力,使用tc,具有0、0.2、1和5毫秒的额外延迟,对应于代表某一类Redis部署的各种LAN设置。
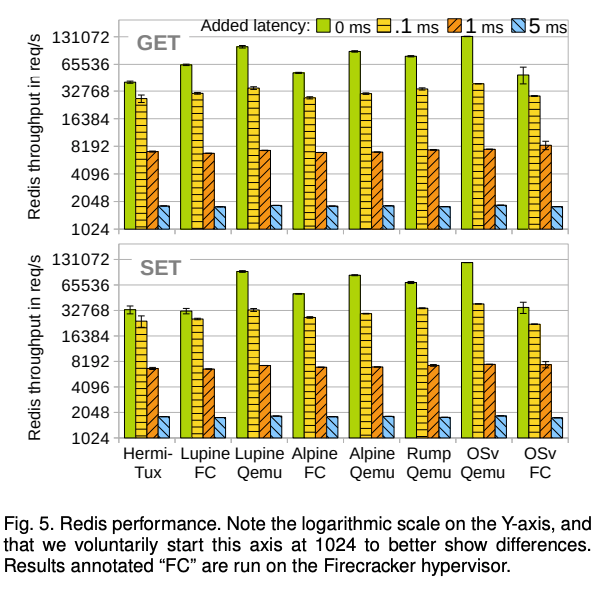
结果如图5所示,在不加任何网络延迟的情况下,该实验代表了对延迟极其敏感的场景,HermiTux比竞争对手慢。它平均比在Qemu上运行的竞争对手慢2.47倍(GET)和2.76倍(SET),在FireCracker上运行时则慢1.34倍(GET)和1.13倍(SET)。这是由于多种因素造成的,尤其是HermiTux未优化的网络驱动程序和TCP/IP堆栈(LWIP),以及缺乏对*virtio的支持。鉴于对网络的成熟支持,*HermiTux很可能将表现与竞争对手相似。此外,通过添加在许多Redis部署场景中不可避免的网络延迟,各种系统之间的性能差异会减小。例如,仅增加0.2毫秒,GET HermiTux仅比Qemu上竞争对手慢1.2倍。从1毫秒的延迟开始,这种减速变得可以忽略不计。这说明HermiTux在很多网络场景中仍然是可行的。下一段将进一步论证,展示我们的系统在吞吐量受限的场景中的效率。
aarch64上的边缘计算基准,边缘计算有望使目前集中在数据中心的计算能力更接近数据源(最终用户、物联网设备等),旨在减少服务延迟。边缘节点预计将比传统服务器更加异构,并且可能特别包括各种ISA的嵌入式设备,例如aarch64。unikernel是这些多租户和资源受限环境的良好后候选者,因为我们使用边缘计算基准评估HermiTux的aarch64端口。
实时数据分析是边缘最重要的工作负载类型之一。我们通过调整PARSEC的StreamCluster(一个执行在线k-means聚类的应用程序)来创建边缘基准,以从网络而不是文件接收其输入数据。通过这个基准,我们旨在重现边缘计算的典型场景,其中一些最终用户/物联网设备生成数据并将其发送给边缘节点进行处理。
在这个实验中,主机服务器(Potato aarch64板)代表边缘节点,并在VM、HermiTux或标准KVM VM中运行Stream Cluster。客户端由一台单独的机器表示,该机器将数据发送给VM,VM依次在该数据上运行集群算法。两台机器都通过本地网络连接,我们将一次迭代的执行时间定义为数据集传输开始到数据完成的时间。

在该数据集上的聚类过程结束,改变数据集的大小,我们在每个系统(HermiTux/Linux KVM)上对每种大小运行10次迭代,并报告一次迭代的平均执行时间,结果如图6所示。
可以看到,HermiTux的性能和Linux相似,所有的数据集大小的平均差异为2.3%。尽管我们在前面的实验(Redis)中看到HermiTux的网络性能比Linux要差一些,但我们注意到,对于这个边缘基准,数据集的网络传输只占迭代执行时间的很小一部分,事实上由于我们使用的嵌入式板的低处理能力,计算阶段占工作的主要部分。增加数据集大小并不能改变这一事实,因为网络和处理的延迟会按比例增长。

系统调用延迟,我们使用LMbench3来测量HermiTux的系统调用延迟,用于null(getpid)、read和write。LMbench报告了一个循环调用100000次相应系统调用的执行时间。图7显示了本地Linux、HermiTux的系统调用处理程序,在HermiTux中运行的带有二进制重写系统调用的静态二进制文件、以及在HermiTux中运行的带有我们替换的单内核感知C库的动态二进制文件的结果。
关于x86-64,与Linux相比,HermiTux(处理程序)的系统调用延迟平均低5.6倍。这是由于多种因素造成的,包括简单和优化的处理程序实现(例如,在HermiTux中没有sysret)和对系统调用本身的简单实现,比我们的二进制重写技术(2.3倍)快,因为这种技术需要执行额外的指令。
关于aarch64,HermiTux的系统调用延迟调用也带来了显著的加速,二进制重写系统调用比使用普通的系统调用处理程序的延迟减少了8.4倍(对于null)。代替一个unikernel C库带来了11.7倍的减少,这只比二进制重写快1.3倍。正如前面提到的,在aarch64中,大多数系统调用可以通过简单的函数调用或分支进行二进制改写操作,而不需要像x86-64中那样进行额外的操作。因此,在aarch64中,libc替换和二进制重写的速度是比较接近的,总体来说由于嵌入式板卡的处理能力比x86-64服务器低,因此aarch64上的绝对延迟更高,读取系统调用的延迟相对较高,这可以解释为LMbench使用/dev/zero作为文件操作的目标,从这个文件中读取相当于将传递给/dev/zero用户缓冲区清零,这是一个更昂贵的操作(memset),比处理在静态二进制文件中重写syscall的调用,比HermiTux中常规处理程序减少2.3倍,这主要是由于抑制了syscall指令引起的中断开销。最后,和HermiTux的处理程序相比,用unikernel-aware C库替代动态程序带来了2.7倍的延迟减少。写入/dev/zero这个文件,相当于一个null操作。由于/dev/zero的吞吐量(与机器相关)的不同,在aarch64上 read和write的差别更大。
论文中还评估了HermiTux的多线程支持,运行NPB CG/LU/MG的OpenMP版本,观察到性能和Linux相似。我们还运行了一个文件系统(Postmark)和一个数据库(SQLite)基准,观察到HermiTux的数据库与Linux、Docker相当,最后我们通过检查和重启NPB基准测试,验证了我们的系统对检查点/重启/迁移的支持。
总体来说,这些结果表明,HermiTux可以带来unikernel的低足迹、快速启动、低系统调用延迟,并且与二进制兼容,对广泛的应用没有明显的性能影响。
八、相关产品
Rumprun和OSv是两个专注于与现有/传统应用程序兼容的unikernels。Rump允许NetBSD内核组件作为库和应用程序一起编译来创建一个unikernel。OSv是从头开始设计的,为云计算应用提供专门的API,并支持未经修改的Linux ABI。然而,应用程序必须被重新编译为可重定位的共享对象,因此Rump和OSv都需要提供源代码,并且应用程序的构建过程必须要扩展以适应这些单核模型的要求。通过LightVM,作者表明与容器相比,unikernel的性能相似/更好,并认为移植到unikernel需要很大的努力。他们提出Tinyx,一个可以自动构建一个精简的Linux内核的系统。HermiTux通过在unikernel蹭上运行未经修改的Linux可执行文件来解决相同的问题,与Linux内核(即使是剥离后的版本)相比,足迹和攻击面都大大减少。但是,绝对来说,像Linux这样的内核不可能达到相同的轻量级和攻击力,与HermiTux等从头开始构建的单核相比,攻击面减少。
Lupin 是 Linux 的 unikernel 版本,它通过配置减⼩内核⼤⼩并使⽤内核模式 Linux 补丁消除⽤⼾/内核边界。尽管它 声称⼆进制兼容,但重要的是要注意,与在系统调⽤级别⼆进制兼容的 HermiTux 不同,Lupin 兼容性是通过动态加载程序和Musl Libc 的修改版本在标准 C 库级别实现的。因此,与 HermiTux 不同的是,对于不动态链接到 Musl 的程序(例如静 态⼆进制⽂件),使⽤ Lupin 的⼀些 unikernels 优势(例如快 速系统调⽤)⽆法实现。UKL [41] 是 Linux 的另⼀个 unikernel版本,但它仍在开发中。
Graphene是⼀个运⾏在 Linux 之上的 LibOS,能够执⾏未经修改的多进程应⽤程序。英特尔 SGX可以增强Graphene的安全性,但这会带来⼤量开销(⾼达2倍)。虽然⼆进制兼容性在容器和某些软件 LibOS(如 Graphene)中是免费的,但我们证明它在 unikernel 中也是可⾏的。诸如 HermiTux 之类的Unikernel 是容器和软件 LibOS 的⼀个有趣的替代品,因为它们受益于硬件辅助虚拟化、强制执⾏的强隔离,其性能开销⾮常低。Google 提出了 gVisor,这是⼀个解决容器安全问题的 Go 框架,通过系统调⽤过滤/插⼊提供⼀定程度的软件隔离。该框架的性能开销不可忽略。
Dune使⽤硬件辅助虚拟化来提供类似进程的抽象,并特别为本地 Linux ⼆进制⽂件实现沙盒机制。需要注意的是,它的隔离模型与 HermiTux 完全不同:Dune 要么将系统调⽤重定向到主机内核,要么阻塞它们,这在阻塞时限制了兼容性,或者在重定向时降低了隔离度。
关于 x86-64 的 Linux API 研究的作者按受欢迎程度对系统调⽤进⾏分类。这些知识可⽤于优先考虑 HermiTux 中的系统调⽤开发。还提到了⼀种系统调⽤⼆进制识别技术,但很少给出实现细节,作者报告说 4% 的调⽤站点识别失败。
最后,与 HermiTux 不同的是,这⾥引⽤的⼀些系统(OSv、LightVM、X-Containers、Graphene-SGX、Lupin)仅⽀持单个 ISA,x86-64。
九、结论
HermiTux 通过提供⼆进制兼容性将本机 Linux 可执⾏⽂件作为unikernel 运⾏,从⽽减轻了应⽤程序程序员移植其软件的⼯作量。在这种模式下,不仅可以在未修改的应⽤程序中免费获得unikernel 的好处,⽽且还可以运⾏以前不可移植的软件。HermiTux 实现了这⼀点,在⼤多数情况下,与Linux相⽐,⽬标开销可以忽略不计,并且在 unikernel 关键指标⽅⾯通常⽐其他 unikernels(OSv、 Rump)表现更好。
HermiTux 可在开源许可下在线获得: https://ssrg-vt.github.io/hermitux/。