加密是最强大的技术之一,每个人每天都在不知不觉中使用它。传输层加密现在已经无处不在,因为它是创建可信赖的Internet的基本工具,它可以保护通过Internet发送到目标目的地的数据。磁盘加密技术可以无所不在地保护您的数据,因为它可以防止任何窃取您设备的人也能够看到您台式机上的内容或阅读您的电子邮件。
这项技术的下一个改进是端到端加密,它是指只有最终用户才能访问其数据的系统,而没有任何中间服务提供商。这类加密的一些最流行的例子是WhatsApp和Signal等聊天应用。端到端加密显著降低了用户数据被服务提供商恶意窃取或不当处理的可能性。这是因为即使服务提供商丢失了数据,也没有人拥有解密数据的密钥!

几个月前,我意识到我的计算机上有很多敏感文件(我的日记,如果你一定知道的话),我担心会丢失,但我不喜欢将它们放入Google Drive或Dropbox之类。尽管Google和Dropbox是绝对值得信赖的公司,但它们不提供加密功能,在这种情况下,我确实希望完全控制自己的数据。
环顾四周,我很难找到符合我所有要求的东西:
- 会同时加密和验证目录结构,这意味着文件名是隐藏的,其他人不可能移动或重命名文件。
- 查看/更改大文件的一部分不需要下载并解密整个文件。
- 是开源的,并且有一个文档化的协议。
所以我开始建立这样一个系统!最终我把它称为“ UtahFS”,其代码在此处提供。请注意,这个系统在Cloudflare的生产中没有使用:它是我在我们的研究团队工作时构建的概念。这篇博客文章的其余部分描述了我为什么要像以前那样构建它,但是如果您想跳过它,则代码仓库中有关于实际使用它的文档。
Storage Layer(存储层)
存储系统的第一个也是最重要的部分是…存储。为此,我使用对象存储,因为它是在别人的硬盘上存储数据的最便宜和最可靠的方法之一。对象存储只不过是一个由云提供程序托管的键值数据库,通常被调整为存储大约几千字节大小的值。有许多具有不同定价方案的不同提供商,例如Amazon S3,Backblaze B2和Wasabi。它们全部都能够存储TB级的数据,并且许多还提供地理冗余。
Data Layer(数据层)
对我来说很重要的一个要求是,在能够读取一部分文件之前,不必下载和解密整个文件。这一点很重要的一个地方是音频和视频文件,因为它能够快速开始播放。另一个例子是ZIP文件:许多文件浏览器都具有浏览压缩档案(例如ZIP文件)的能力,而无需将其解压缩。要启用此功能,浏览器需要能够读取存档文件的特定部分,仅解压缩该部分,然后移动到其他位置。
在内部,UtahFS从不存储大于配置大小(默认为32 KB)的对象。如果文件中的数据量超过该数据量,则该文件将分成多个对象,这些对象通过跳表连接。跳表是链接列表的稍微复杂一点的版本,它允许读者通过在每个块中存储指向比指向前一跳更远的其他指针来快速移动到随机位置。
当跳表中的块不再需要时,因为文件已被删除或截断,它们将被添加到特殊的“回收站”链接列表中。例如,当需要在其他位置使用块时,可以回收垃圾列表的元素,以创建新文件或将更多数据写入现有文件的末尾。这将最大限度地重用,意味着仅当垃圾箱列表为空时才需要创建新块。一些读者可能认为这是《计算机编程艺术:第一卷,2.2.3节》中描述的链接分配策略!
使用链接分配的根本原因是,对于大多数操作而言,这是最有效的。 而且,这是一种分配内存的方法,该方法将与我们在接下来的三个部分中讨论的加密技术最兼容。
Encryption Layer(加密层)
既然我们已经讨论了如何将文件分成块并通过跳表进行连接,我们就可以讨论如何实际保护数据。这有两个方面:
第一个是机密性,它对存储提供者隐藏每个块的内容。 只需使用AES-GCM加密每个块,并使用从用户密码中获得的密钥,即可实现这一点。
该方案虽然简单,但不提供前向保密或后向安全。前向保密意味着,如果用户的设备遭到破坏,攻击者将无法读取已删除的文件。后泄露安全性意味着一旦用户的设备不再泄露,攻击者将无法读取新文件。不幸的是,提供这两种保证之一意味着在用户的设备上存储加密密钥,这些密钥需要在设备之间同步,如果丢失,将使存档无法读取。
此方案也无法防止脱机密码破解,因为攻击者可以获取任何加密的块,并一直猜测密码,直到找到有效的块为止。通过使用Argon2(这使得猜测密码更为昂贵)和建议用户选择强密码,可以在一定程度上缓解这种情况。
我肯定会在将来改进加密方案,但认为上面列出的安全属性对于初始发行版来说太困难和脆弱。
Integrity Layer(完整性层)
数据保护的第二个方面是完整性,它确保存储提供程序没有更改或删除任何内容。这是通过在用户数据上构建Merkle树来实现的。Merkle树在我们关于证书透明性的博客文章中得到了深入的描述。Merkle树的根哈希值与版本号相关联,该版本号随每次更改而递增,并且根哈希值和版本号均使用从用户密码派生的密钥进行身份验证。这些数据存储在两个位置:对象存储数据库中的一个特殊密钥下,以及用户设备上的一个文件中。
每当用户想从存储提供程序读取一块数据时,他们首先请求远程存储的根目录,并检查它是否与磁盘上的相同,或者版本号是否大于磁盘上的版本号。检查版本号可防止存储提供程序将存档还原为未检测到的以前(有效)状态。然后,可以根据最新的根散列验证读取的任何数据,该散列可防止任何其他类型的修改或删除。
在此处使用Merkle树的好处与“证书透明性”的好处相同:它使我们能够验证单个数据,而无需立即下载并验证所有内容。 另一个用于数据完整性的常用工具称为消息身份验证码(Message Authentication Code,简称MAC),虽然它既简单又有效,但它无法只进行部分验证。
我们使用Merkle树不能防止的一件事是分叉,在分叉中,存储提供商向不同的用户显示不同版本的存档。然而,检测fork需要用户之间的某种流言蜚语,这已经超出了最初实现的范围。
Hiding Access Patterns(隐藏访问模式)
Oblivious RAM, or ORAM,是一种用于以随机方式对随机存取存储器进行读写的加密技术,它可以从存储器本身中隐藏执行了哪个操作(读或写)以及对该操作执行到了存储器的哪一部分!在我们的例子中,“内存”是我们的对象存储提供程序,这意味着我们要向他们隐藏我们正在访问的数据片段以及访问的原因。这对于防御流量分析攻击很有价值,在这种攻击中,对UtahFS这样的系统有详细了解的对手可以查看其发出的请求,并推断加密数据的内容。例如,他们可能会看到您定期上传数据,几乎从不下载,并推断您正在存储自动备份。
ORAM最简单的实现是始终读取整个内存空间,然后使用所有新值重写整个内存空间,只要您想读取或写入单个值。一个观察内存访问模式的对手将无法判断你真正想要的值,因为你总是触摸所有东西。然而,这将是极其低效的。
我们实际使用的结构称为Path ORAM,它稍微抽象了一点这个简单的方案,使其更有效。首先,它将内存块组织成二叉树,其次,它保留一个客户端表,该表将应用程序级指针映射到二叉树中的随机叶。诀窍是允许一个值存在于任何内存块中,该内存块位于指定叶和二叉树根之间的路径上。
现在,当我们要查找指针指向的值时,我们在表中查找它的指定叶,并读取根和该叶之间路径上的所有节点。我们正在寻找的价值应该在这条路上,所以我们已经拥有了我们需要的!在没有任何其他信息的情况下,对手看到的只是我们从树上读到一条随机路径。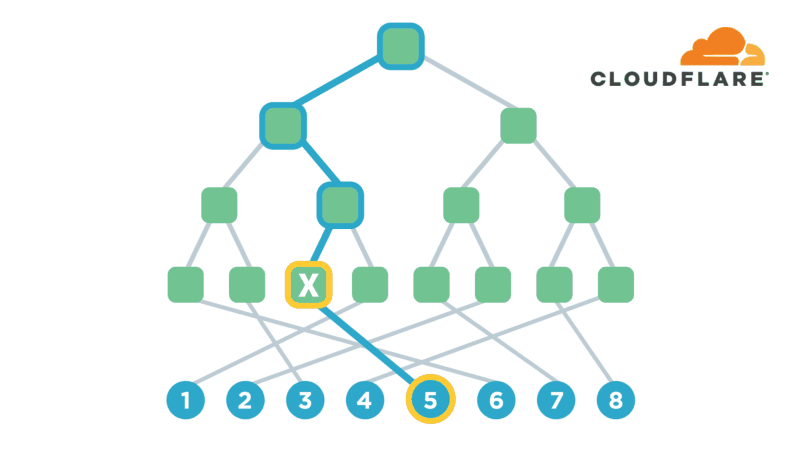
但是,我们仍然需要隐藏我们是在读还是在写,并重新随机分配一些内存,以确保此查询不会与将来的其他查询相关联。 所以为了重新随机化,我们将刚读取的指针分配给新叶子,然后将值从存储在其之前的块中移到新叶子和旧叶子的父块中。(在最坏的情况下,我们可以使用根块,因为根是所有内容的父对象。)一旦将值移动到适当的块中,并完成应用程序的使用/修改,我们将对提取的所有块重新加密并将其写回内存。这将把值放在根和它的新叶之间的路径中,同时只改变我们已经获取的内存块。
这个结构很好,因为我们只需要触摸分配给二叉树中单个随机路径的内存,这是相对于内存总大小的对数工作量。但即使我们一次又一次地读同一个值,我们每次都会从树上碰到完全随机的路径!但是,额外的内存查找仍然会导致性能损失,这就是为什么ORAM支持是可选的。
Wrapping Up(结束语)
在这个项目上的工作对我来说是非常有益的,因为虽然系统的许多单独的层看起来很简单,但它们是许多改进的结果,并很快形成了一些复杂的东西。在这个项目上的工作对我来说是非常有益的,因为虽然系统的许多单独的层看起来很简单,但它们是许多改进的结果,并很快形成了一些复杂的东西。
原文链接:https://blog.cloudflare.com/utahfs/ 开源地址:https://github.com/cloudflare/utahfs