独善其身
工匠之芯,技术狂热追求者,开源社区爱好者,一个记录成长的站点。


云原生|区块链|信息安全从业者,web3.0生态研究与建设者。
我不声不响的,带来自己这个包袱,尽管我不喜爱自己,但我还是悄悄打开,我以前睡在黑暗的壳里,我的脑袋就是我的边疆,我的呼吸,一直在证明,树叶飘飘。
我无限的热爱着新的一日,今天的太阳 今天的马 今天的花楸树,使我健康 富足 拥有一生,从黎明到黄昏,阳光充足,胜过一切过去的诗。

IceFireDB is a database built for web3 and web2. It strives to fill the gap between web2 and web3 with a friendly database experience, making web3 application data storage more convenient, and making web2 applications easier to decentralize data and access blockchain.

HiveMesh revolutionizes application runtimes by bridging Web2.0 and Web3.0. It offers advanced WASM runtimes, decentralized storage, trusted computing, AI model interaction, decentralized identity verification, and cross-chain computing.

Decentralized AI search engine emphasizing user data sovereignty while delivering personalized search experiences.

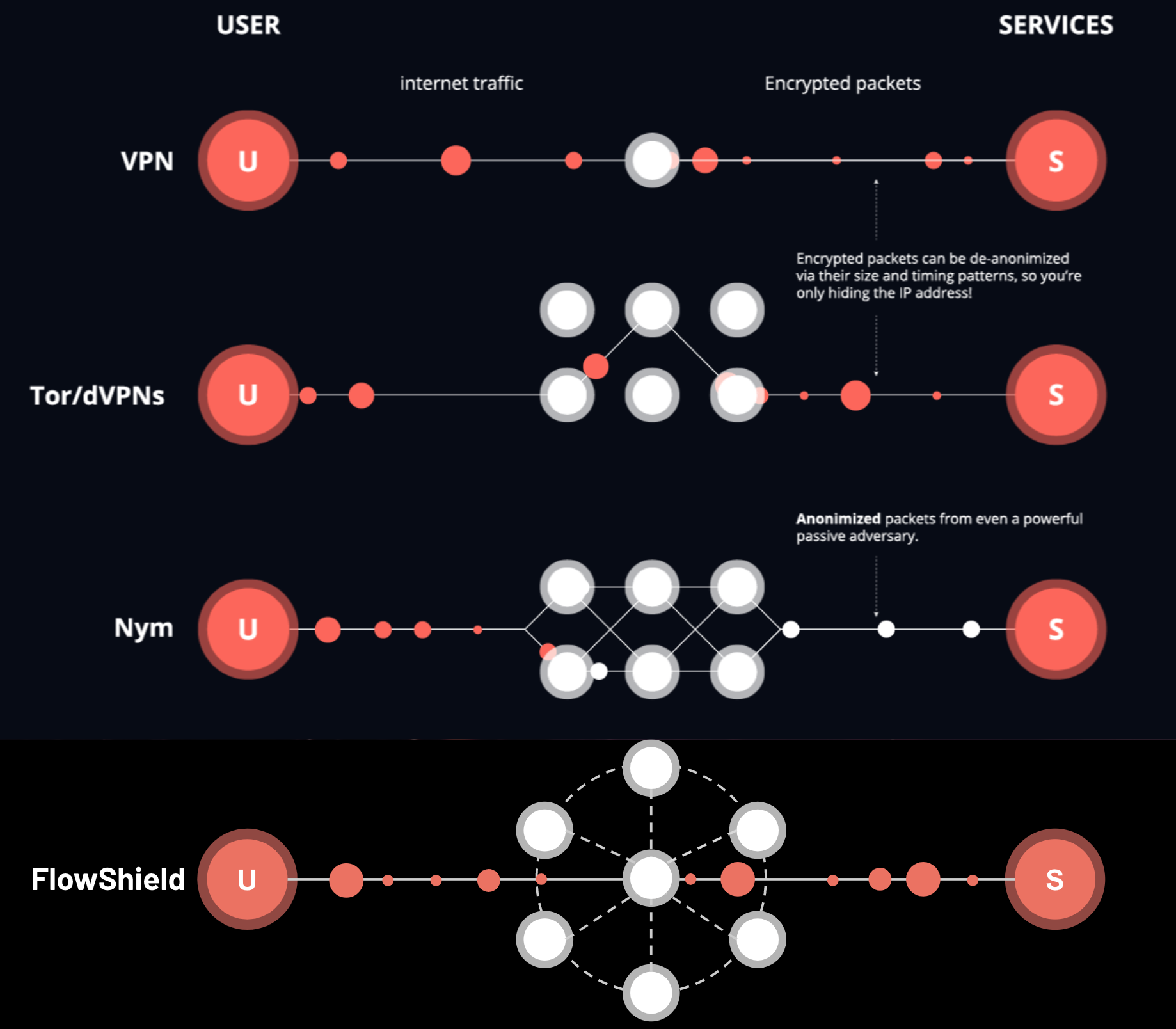
FlowShield aims to build a global decentralized web3 privacy data retrieval security network system, in order to help users regain the network privacy and security information eroded by giants under web2.

The IceGiant database DeFi protocol aims to realize the data asset conversion, management and transaction of data, and create more value and circulation possibilities for data. IceGiant uses DeFi technology and NFT technology to convert data into digital assets and provide efficient, safe and sustainable data financial capabilities.

Next-Generation Time Series Database for AI and Web3.0,built on an in-memory model, this cutting-edge time series database offers ultra-high-speed write and query performance. It seamlessly integrates advanced data AI capabilities and blockchain technology, delivering a faster, smarter, and more secure experience for managing time series data.